
We are on some web page, we encounter an input field, and we start typing. As we type, we start seeing partial results appear based on the few characters we have already typed:
As we keep typing, the partial results keep getting refined until it nearly predicts the word or phrase we were trying to type fully. This type of autocompletion-like interaction is one we take for granted these days. Almost all of our UIs have some form of it. Why is this interesting for us at this very moment right now?
Behind the scenes, there is a very good chance, the data structure powering this autocomplete capability is the star of this tutorial, the trie (sometimes also called a prefix tree). In the following sections, we are going to learn more about it.
Onwards!
Let’s get the boring textbook definition out of the way: A trie (pronounced as “try”) is tree-based data structure that is ideal for situations involving adding, deleting, or finding strings or sequences of characters.
Yeah...that isn’t particularly helpful in explaining what a trie is or does:

This calls for an example and visual walkthrough, and we’ll look at this across the most common operations we’ll be performing on a trie.
What we want to do is store the word apple inside a trie. The first thing we do is break our word into individual characters a, p, p, l, and e. Next, it’s time to start building our trie tree structure.
The start of our trie is an empty root node:

Our next step is to take the first letter (“a”) from the word (“apple”) we are trying to store and add it to our trie as a child of our root node:
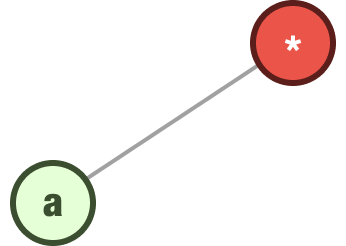
We repeat this step for the next letter (“p”) and add it as a child of our a node:
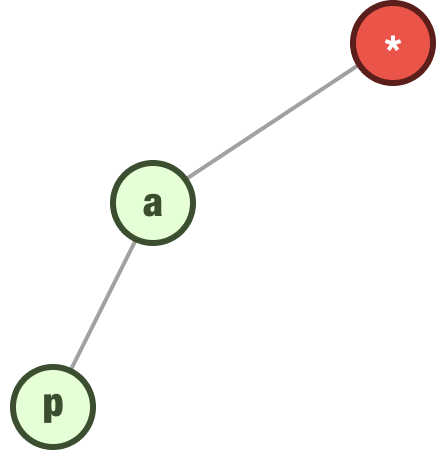
We keep taking each letter of our word and adding it as a child of the previous letter. For our word apple, the final trie structure would look as follows:
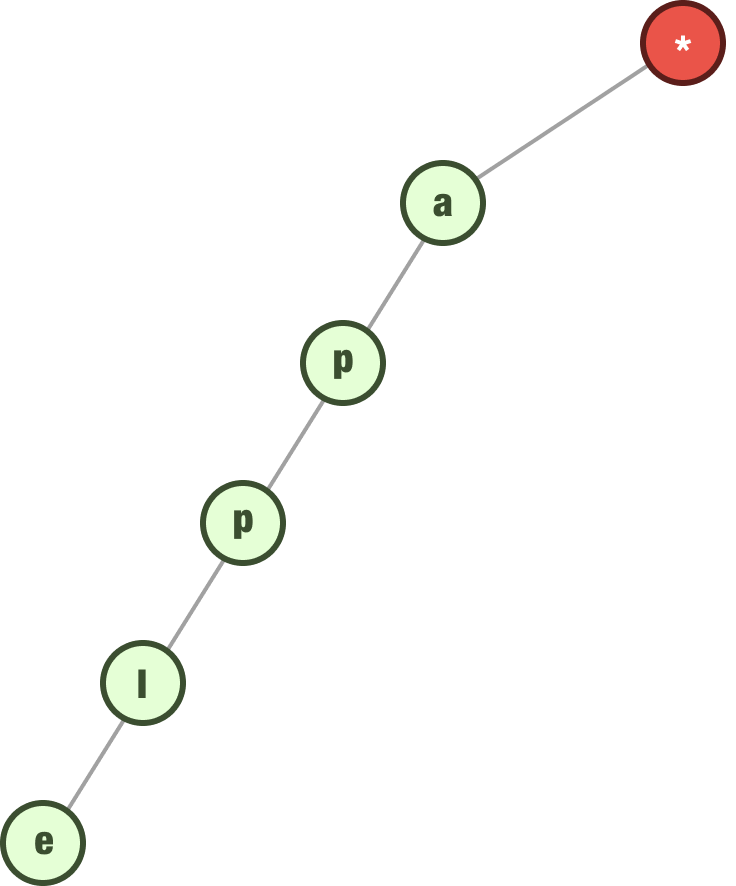
There is one additional thing that we do once our entire word is represented in the tree. We tag the last letter of our input to indicate that it is complete:
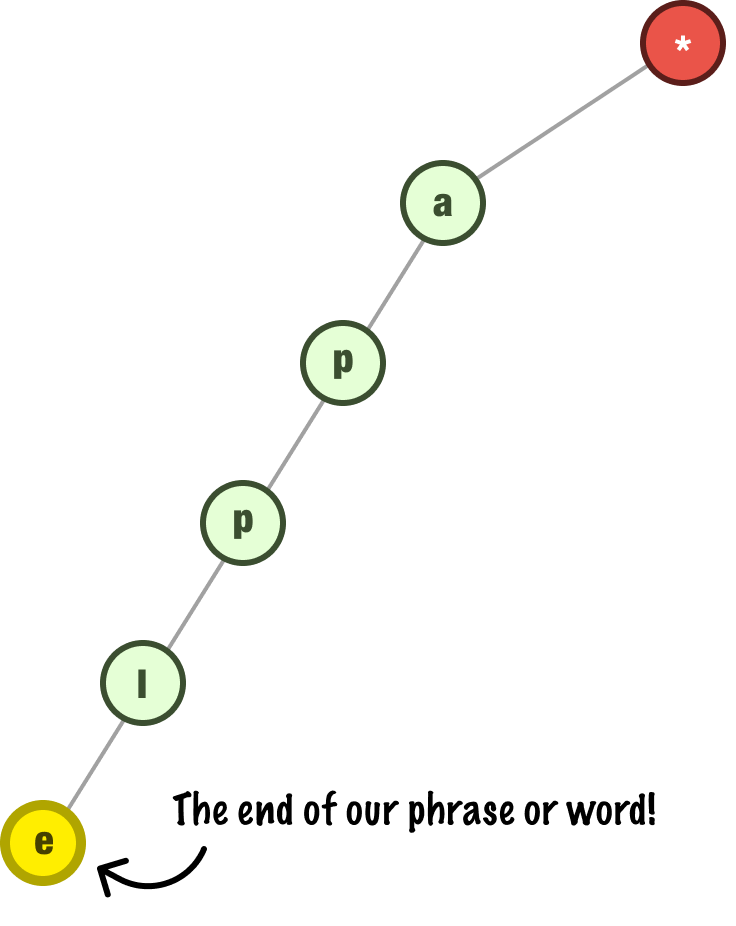
We’ll see later why marking the end is important. For now, let’s go ahead and add a few more words to our trie. We are going to add the words cat, dog, duck, and monkey. When we add cat and dog, our trie will look as follows:
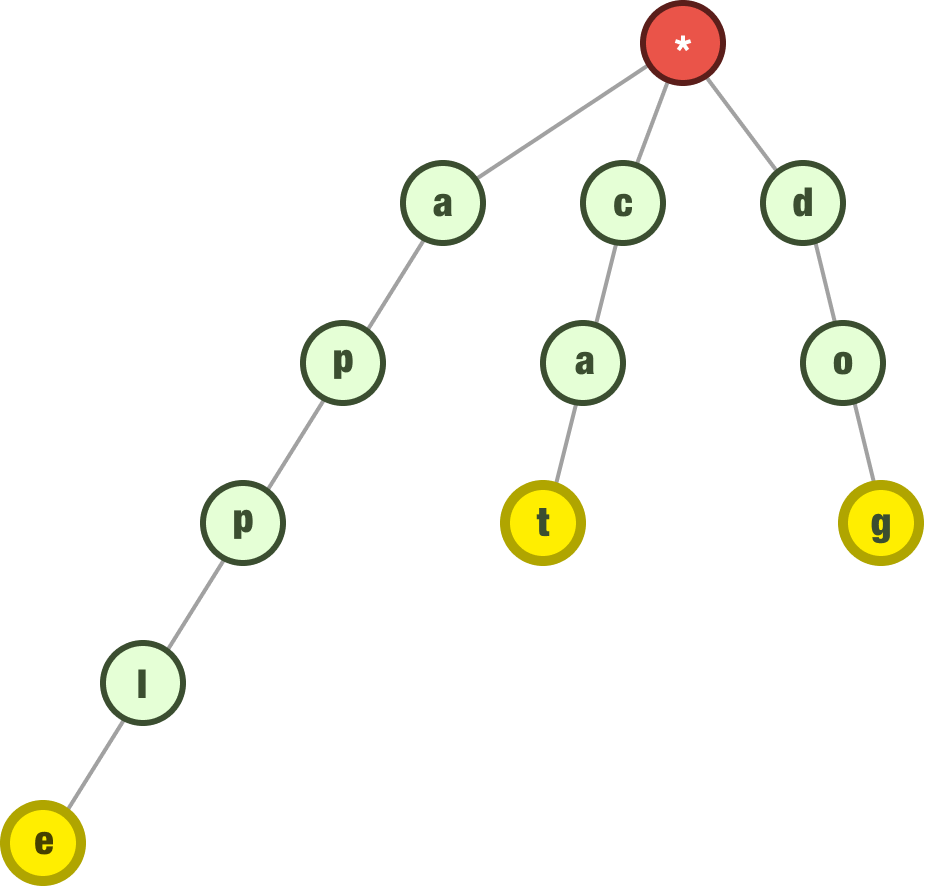
The next word we are going to add is duck. Notice that the first letter of our word is d, and we already have a d node at the top as a child of our root. What we do is start from our existing d node instead of creating a new d node. The next letter is u, but we don’t have an existing child of d with the value of u. So we create a new child node whose value is u and continue on with the remaining letters in our word.
The part to emphasize here is that our letter d is now a common prefix for our dog and duck words:

The next word we want to add is monkey, and this will be represented as follows once we add it to our tree:
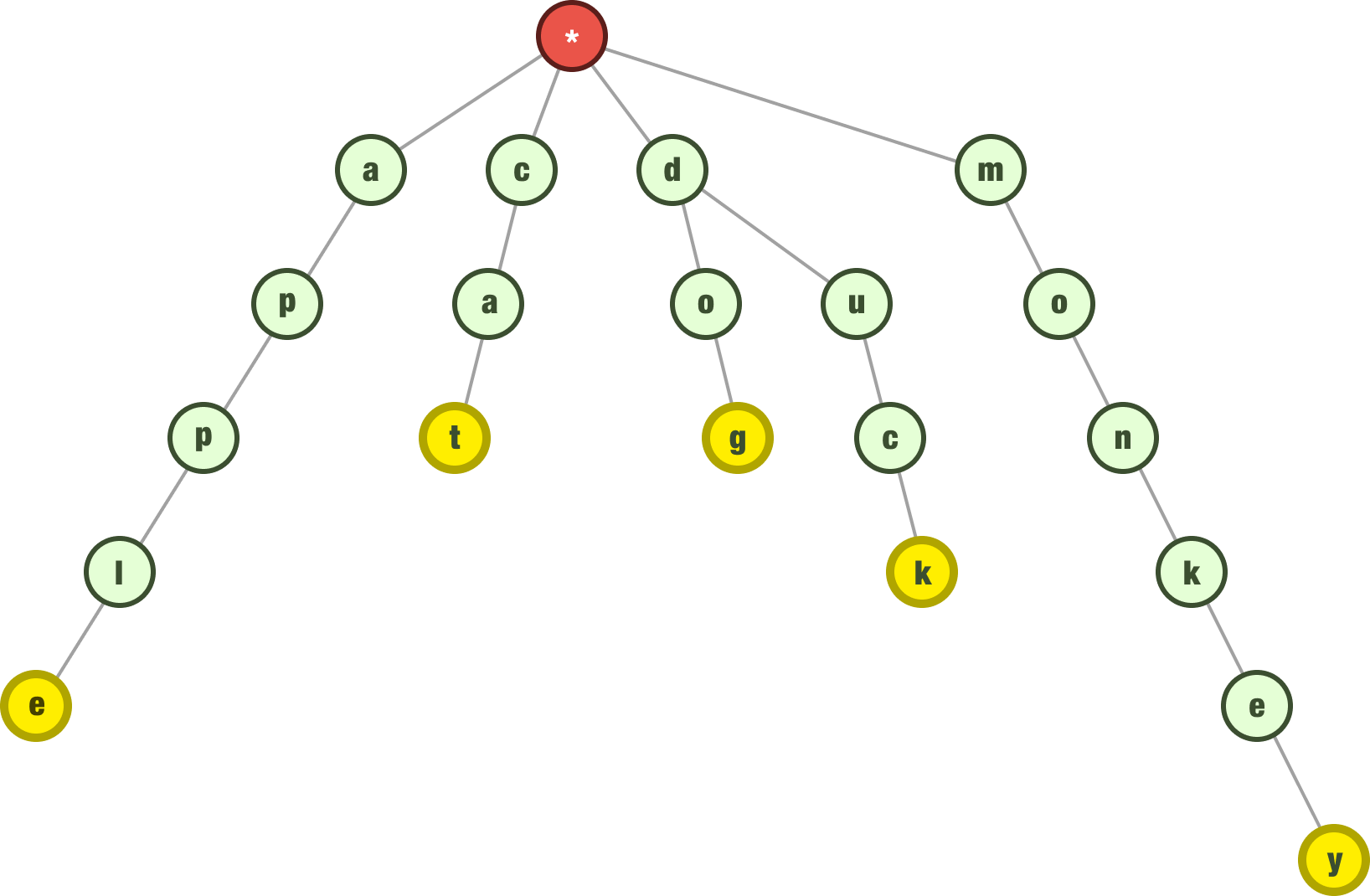
Because the starting letter m is not already a child of our root, we create a new node for m. Every subsequent letter in the word monkey follows from it. We are almost done here, so let’s go a little faster as well.
The next word we want to represent is dune. We know the letters d and u are already in our trie, so what we do is add the letters n and e that build off the common prefix, du:
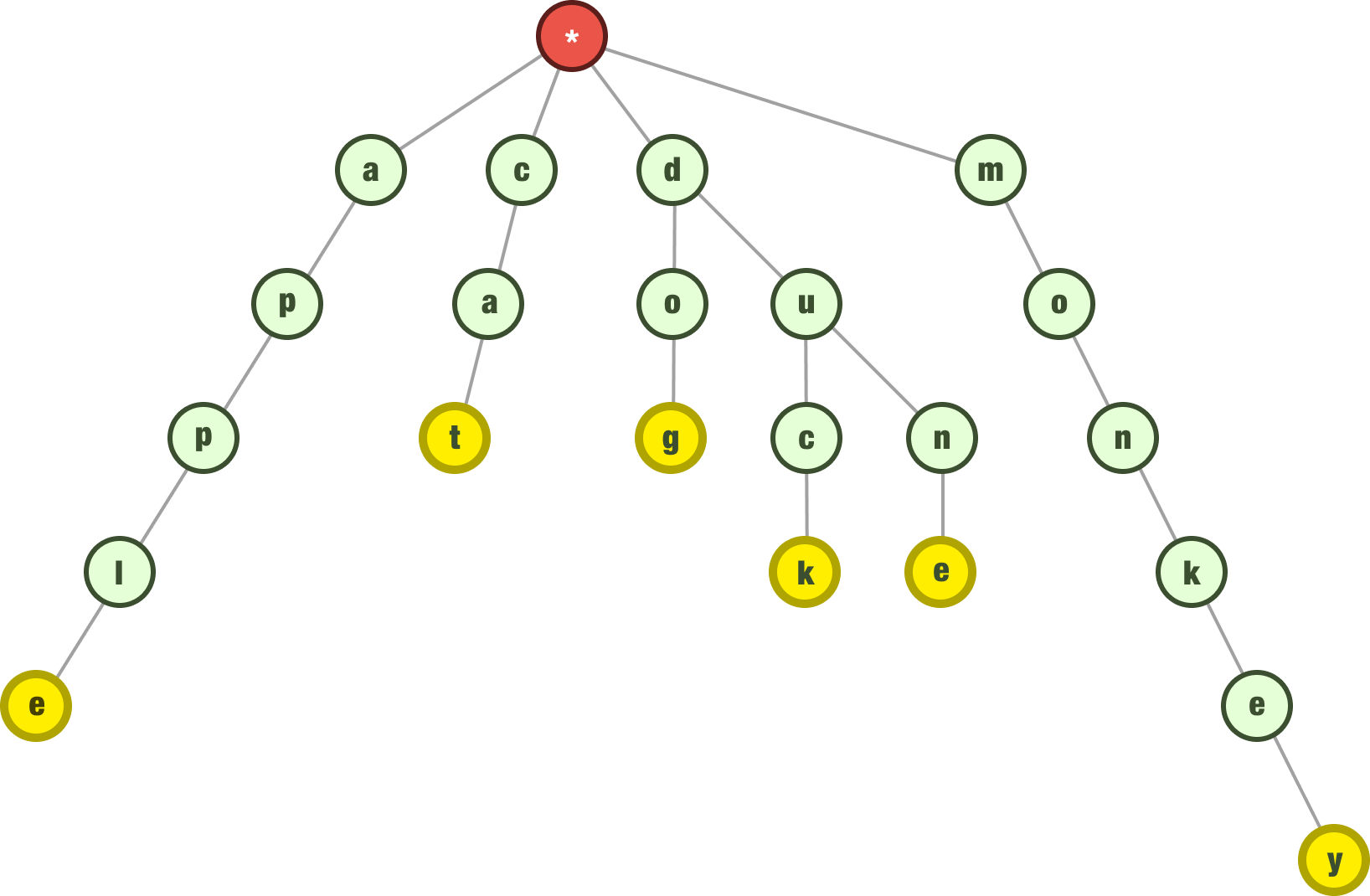
The next two words we want to add are app and monk. Both of these words are contained within the larger words of apple and monkey respectively, so what we need to do is just designate the last letters in app and monk as being the end of a word:
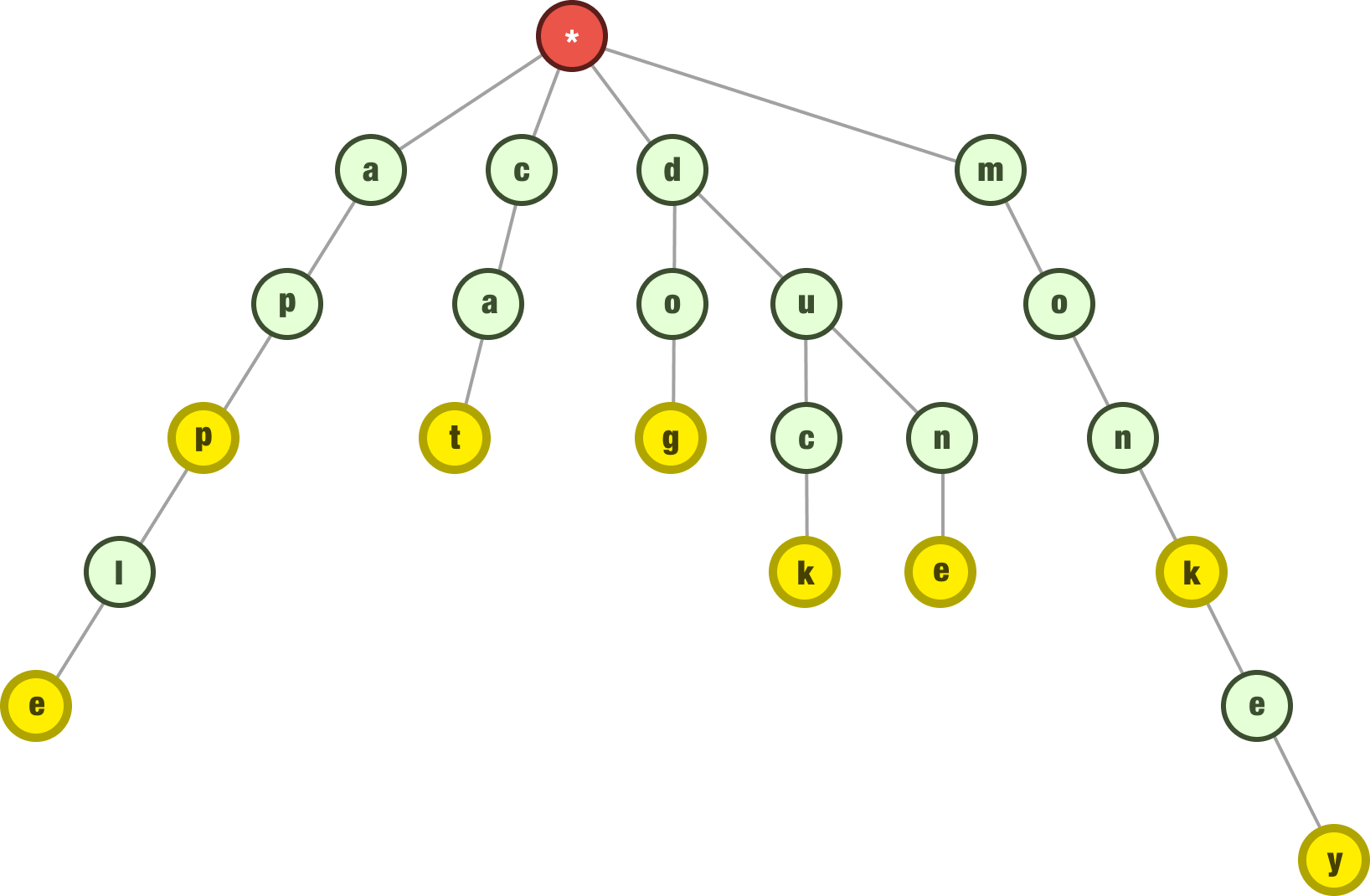
Ok. At this point, our trie contains the following words apple, app, cat, dog, duck, dune, monkey, and monk. We have enough items in our trie now. Let’s look at some additional operations.
Once we have our trie filled in with our data, one of the most common operations we’ll perform is searching our trie to see if a value or values exist in it. Continuing with our trie from earlier, let’s say we want to see if the word eagle exists. What we do is break our input word into its individual characters: e, a, g, l, e.
We check if the first letter exists as a child of our root node:
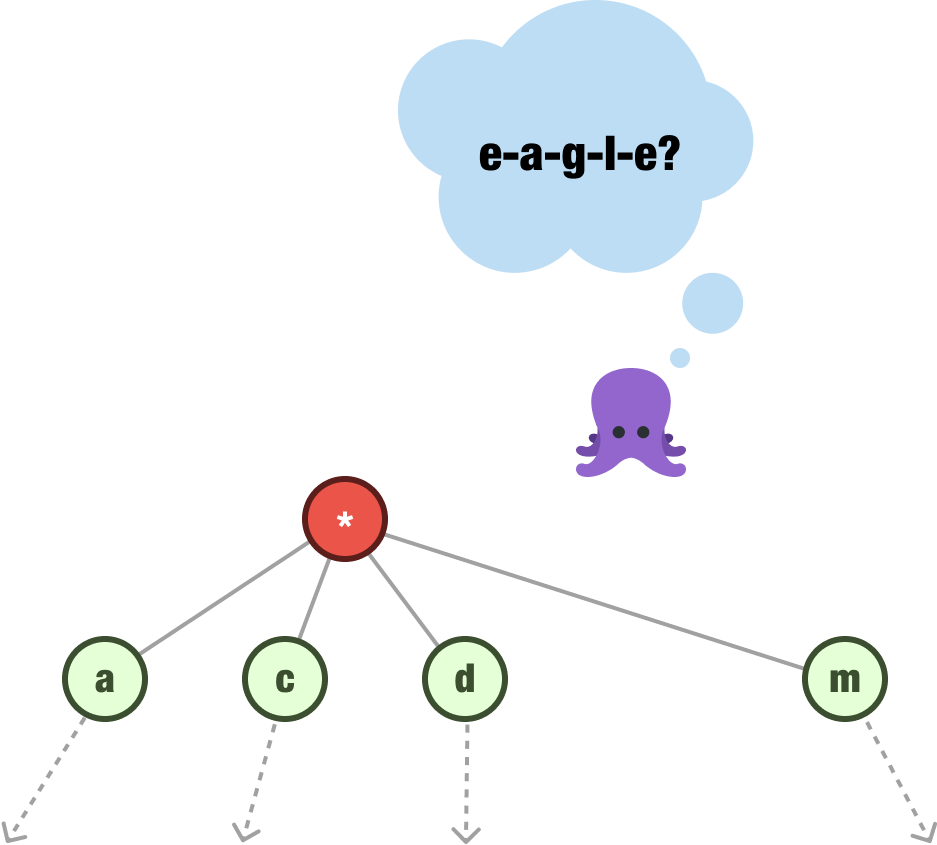
The starting letters we have are a, c, d, and m. The letter e isn’t present, so we can stop the search right here itself. If the first letter isn’t available, we can safely state that all subsequent letters won’t be present either.
Our next task is to see if the word monk exists in our trie. The process is the same. We check if the first letter of the word we are looking for (m) exists as the first letter in our trie. The answer is yes:
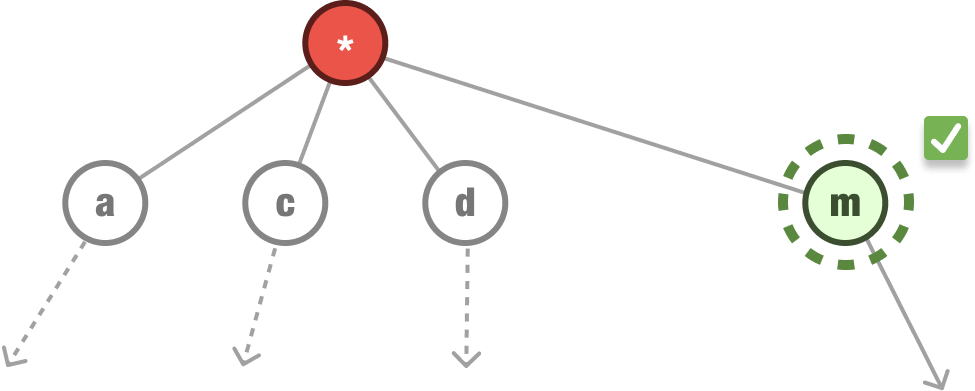
We then continue down the path of the m node and check if the second letter (o) is an immediate child:
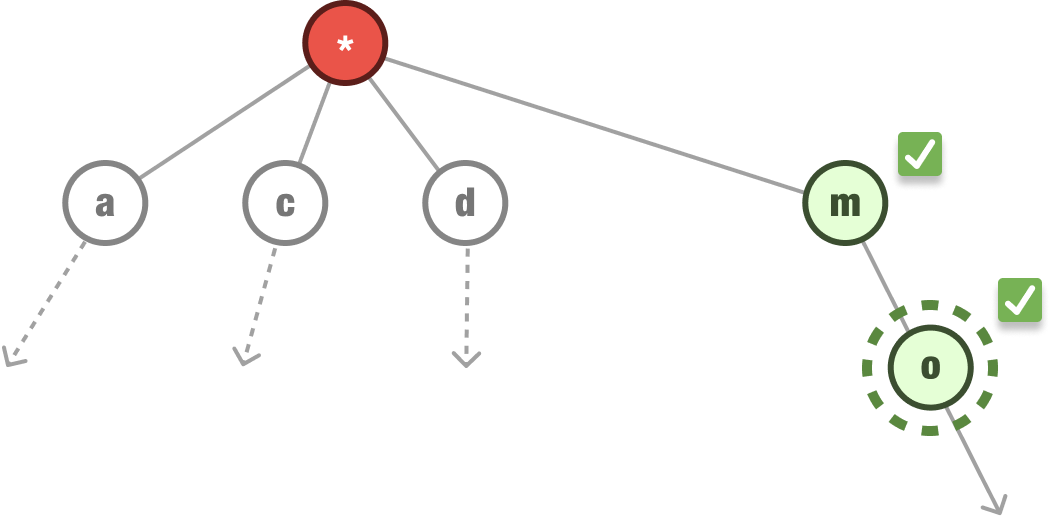
In our case, o is an immediate child of m. Notice that our search is very narrowly focused on the branches of the m node only. We don’t care about what is happening in the other nodes. Continuing on, now that our first two letters match, we keep repeating the same steps and checking if the third and fourth letters match as well:
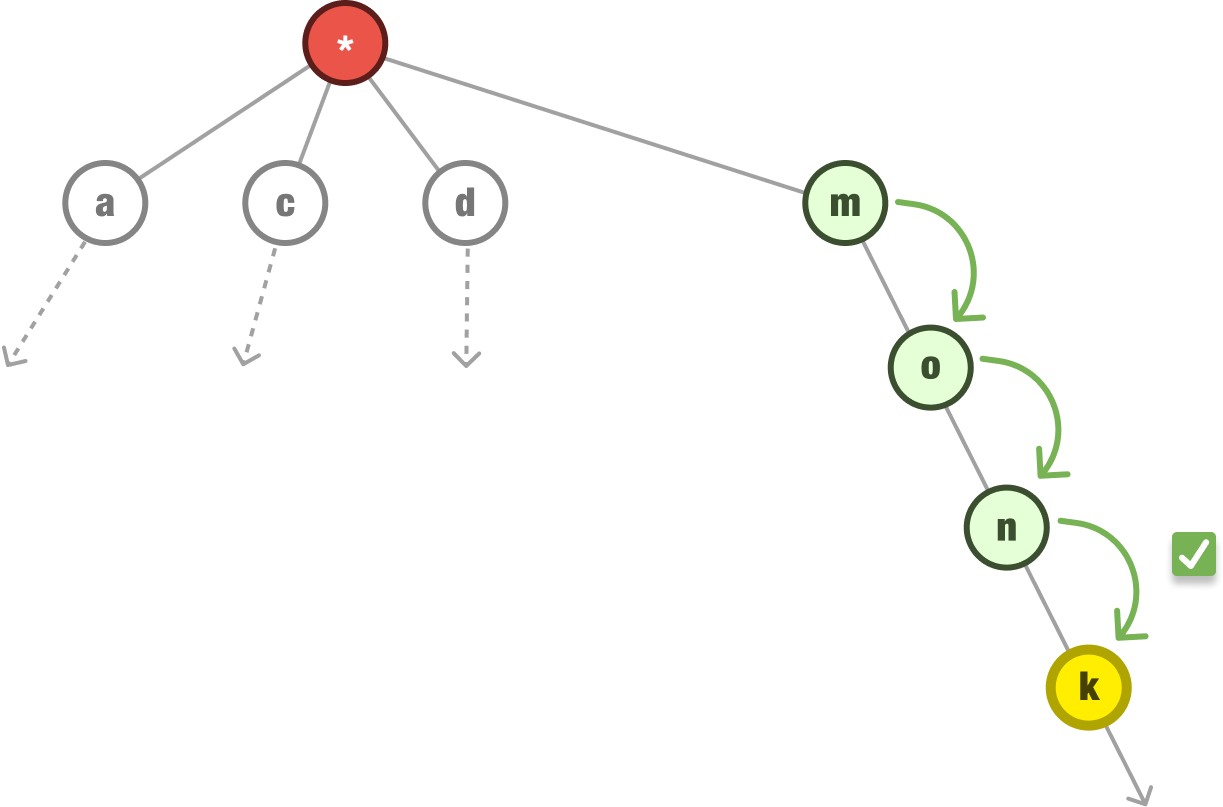
The remaining letters in monk match what we have in our trie. Depending on the operation we are doing, there may be one more step:
This distinction between a complete word and prefix when we are searching our trie becomes important in various situations. The complete word search is important if we want to check if monk was added to our trie at some point as a full word. If we wanted to find all words that start with monk, then the prefix search is the approach we use. We’ll see some examples of both of these approaches when diving into our implementation later.
The last step we will look at is how to delete an item from our trie. Because we went into detail on how to add and find items in our trie, how we delete items is more straightforward. There are a few additional tricks we need to keep in mind. In our trie, let’s say that we want to delete the word duck:
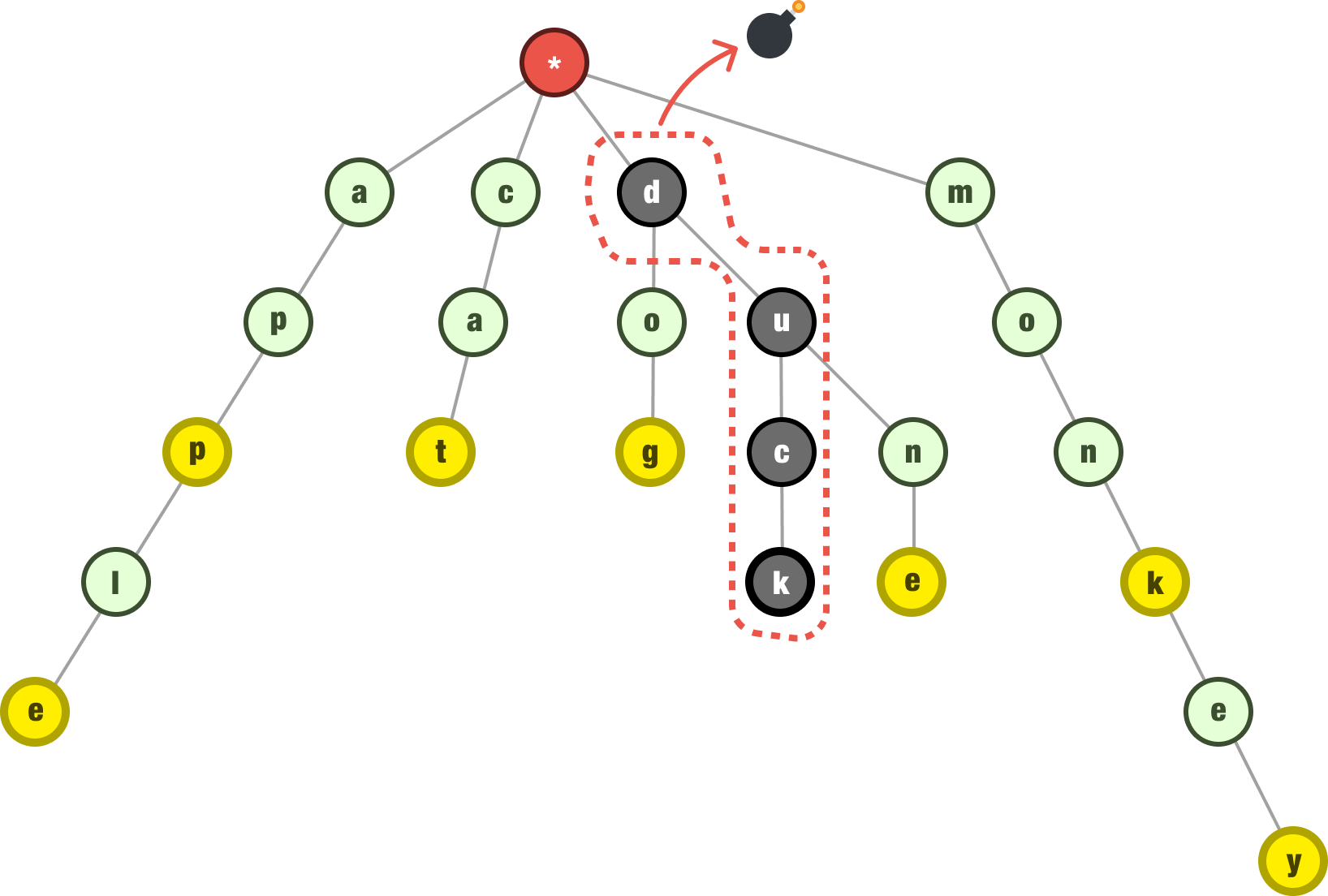
What we can’t do is just traverse this tree and delete all the characters. The reason is that:
So, what do we do? Well, we have our three checks to perform. We first check to make sure the word we are deleting exists in our tree, and we check the last node by making sure it is flagged as being the end of our word. If all of that checks out, at this point, we are at the last character of the word we are interested in removing:
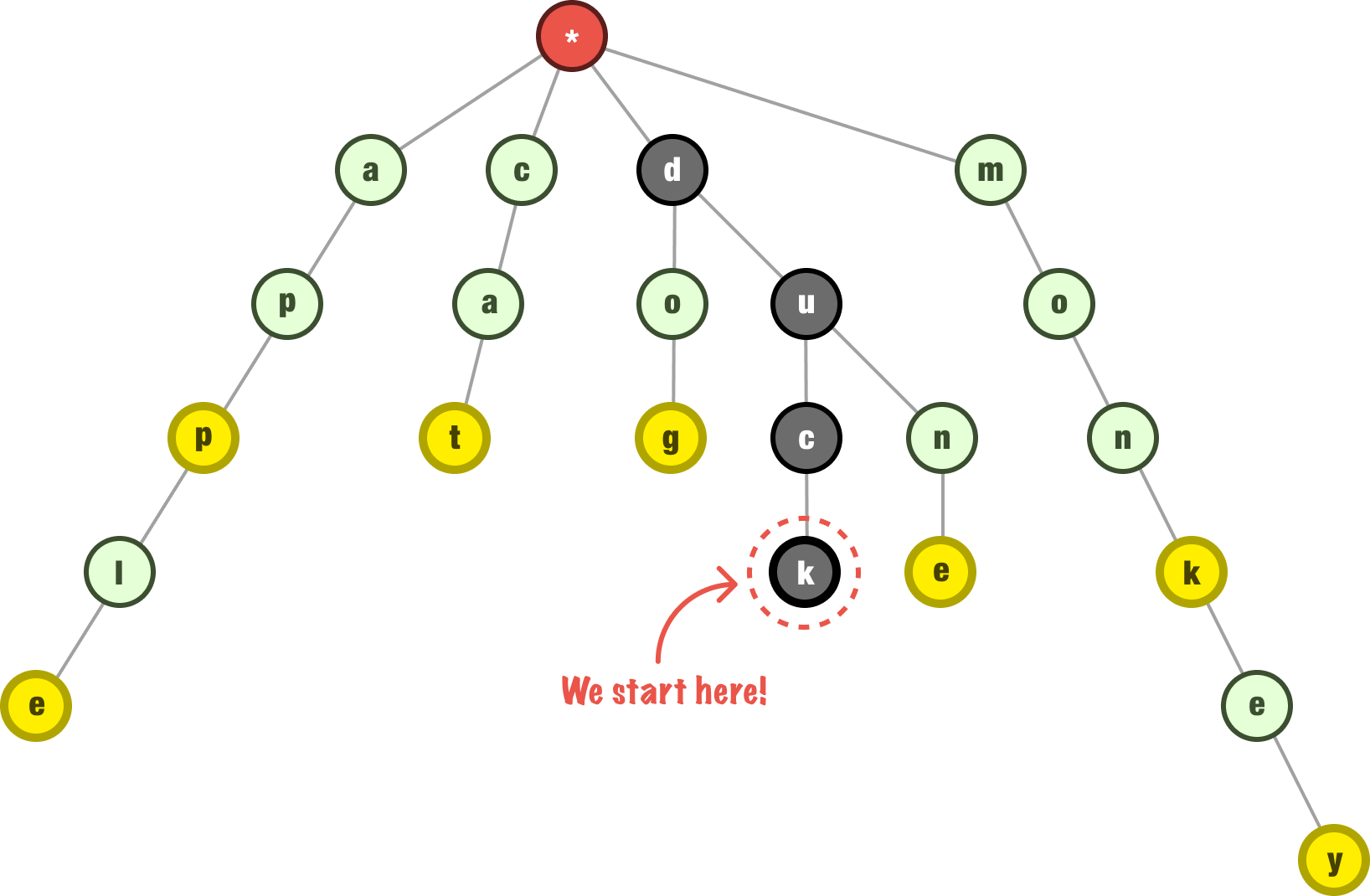
What we do next is traverse up our tree in reverse order. For each letter we encounter, we check if the current node has no other children and is not the end of another word. If the node we encounter passes these checks, we remove the node and keep moving up the tree. This process continues until we encounter a node that has other children or is the end of another word. At that point, the deletion process stops.
For our example where we want to remove duck from our trie, we start at the end with the letter k. This node is safe to delete, so we delete it. We then move up to the letter c. This node is also safe to delete, so our trie now looks as follows:
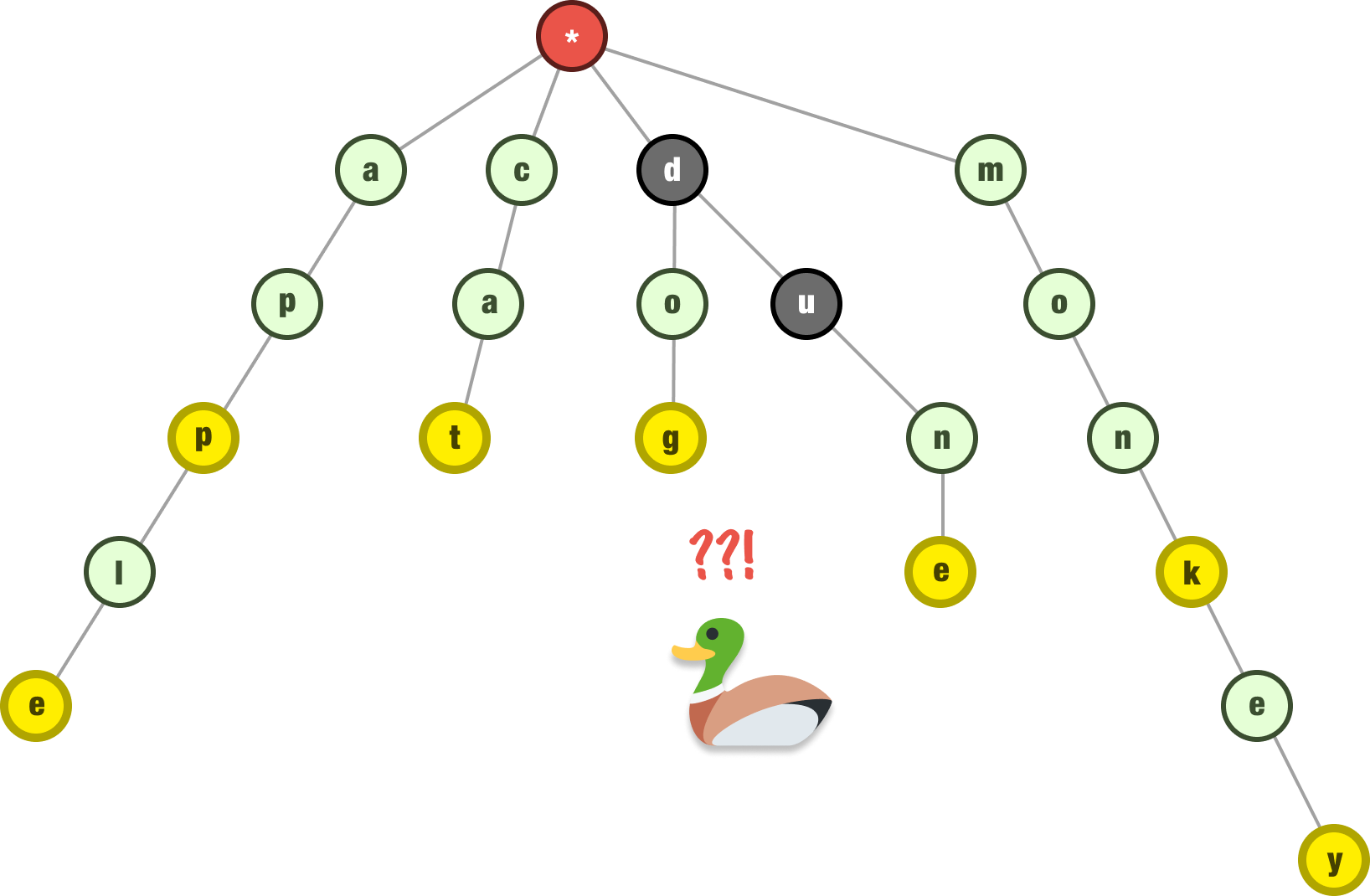
The next letter we run into is u, and u has additional children. It is a shared prefix where it is on the path to the letter n that is part of the word dune. At this point, this means we can stop our deletion operation. It doesn’t matter what happens beyond this point, for other word(s) rely on the preceding letters of d and u to be present.
When we started looking at tries in the previous section, we had the following definition:
A trie is tree-based data structure that is ideal for retrieving strings or sequences of characters.
Let’s start with the obvious one. Our trie is a tree-based data structure. We can visually see that is the case:
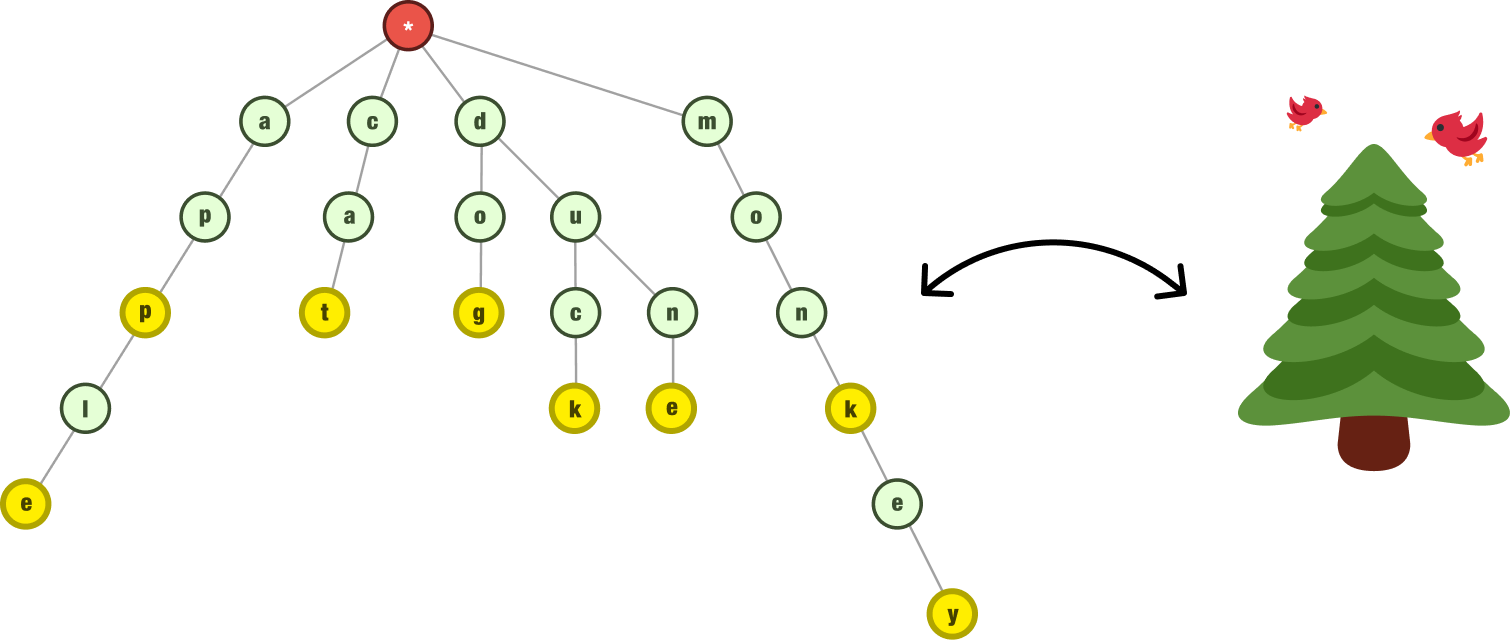
When we examine how our data is structured, the tree similarity still holds. We have a series of nodes where the value of each node is a singular part of a larger piece of data. In our example, the singular part is the letter. The larger piece is the word.
Now, let us get to the really big elephant in the room: What makes tries efficient for retrieving strings or sequences of characters? The answer has a lot to do with what we are trying to do. Where a trie is helpful is for a very particular set of use cases. These cases involve searching for words given an incomplete input. To go back to our example from earlier, we provide the character d and our trie can quickly return dog, duck, and dune as possible destinations:
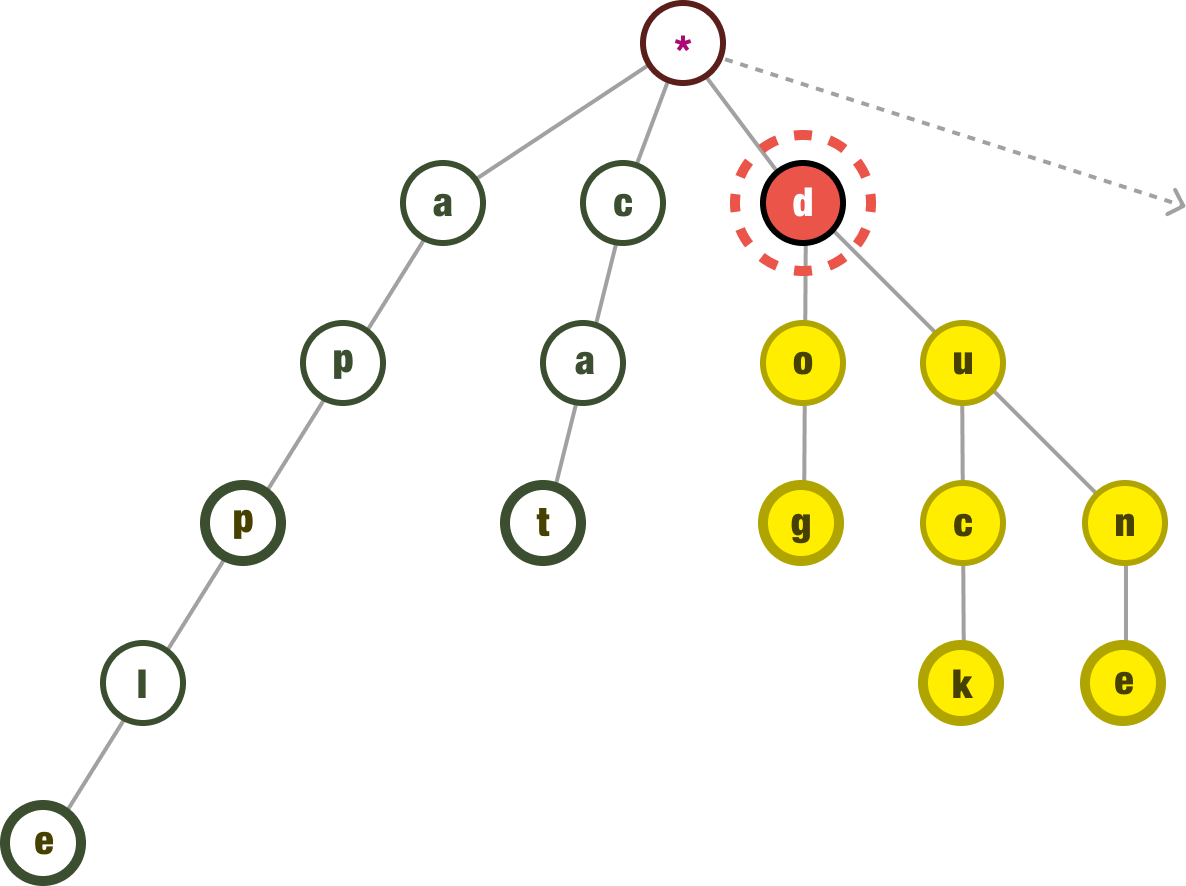
If instead what we are doing is checking if our input characters (ie: d-o-g) is a word or not, then the trie is the wrong data structure. We probably want something like a hash map that can quickly tell us if our complete input is among a set of stored values.
Now, what are the situations where we may have incomplete input that may still have just enough detail to give us a shortcut to a final value? Let’s take a look at a few of them:
Autocomplete and predictive text: Reiterating a point we started off our look at tries with, when we start typing a word or a phrase in a search engine, email client, or messaging app, we often see suggestions that complete our input:
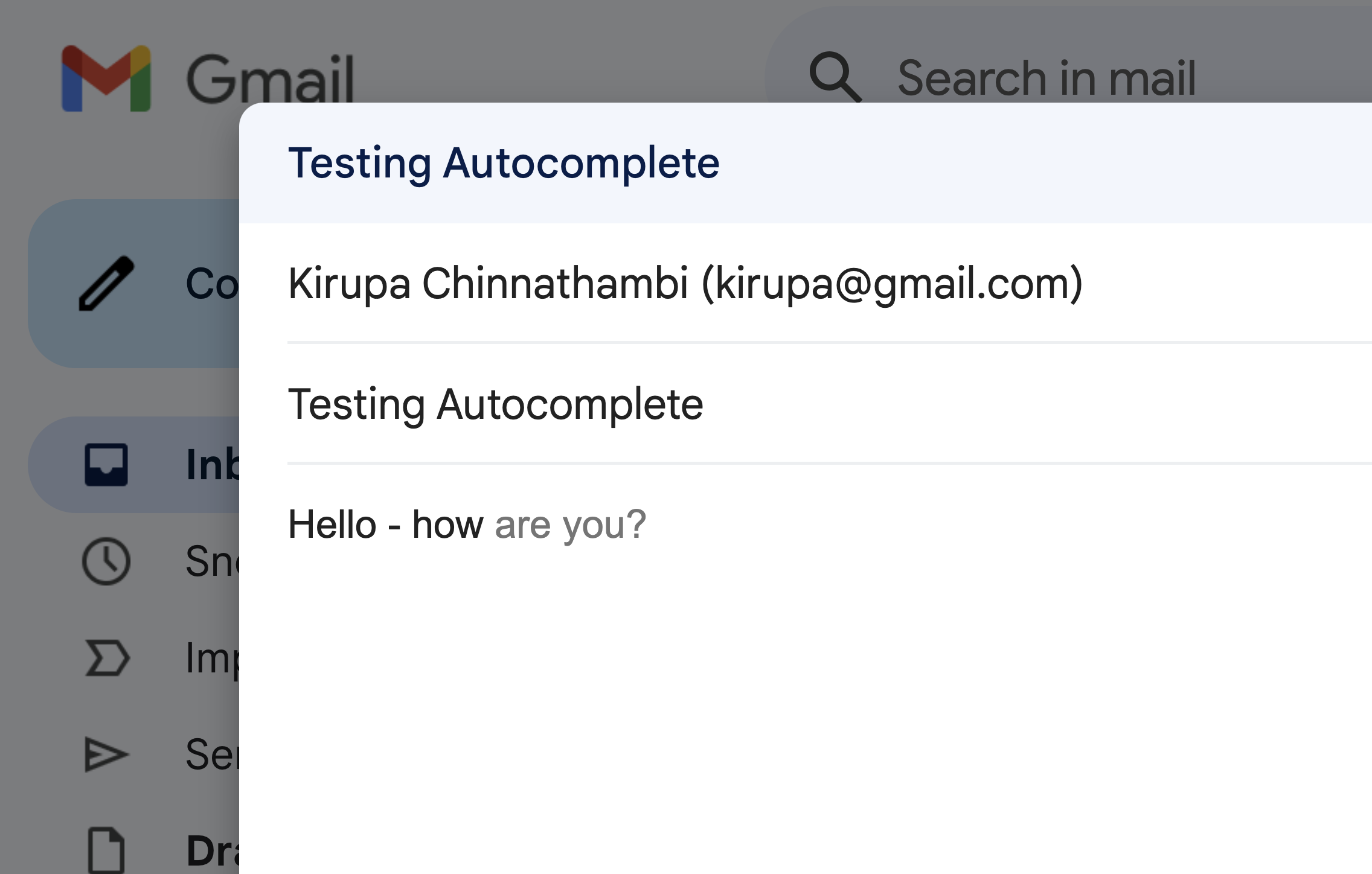
Tries are useful for implementing autocomplete functionality pretty efficiently. Each node in the trie represents a character, and each point leading from there represents the possible next characters. By traversing the trie based on user input, we can quickly find and suggest the most likely completions...such as monkey and monk when our input is m.
Spell checking and correction: Spell checkers rely on dictionaries to identify and correct misspelled words. Tries can be used to store a dictionary efficiently, allowing fast lookup and suggestions for alternative words:
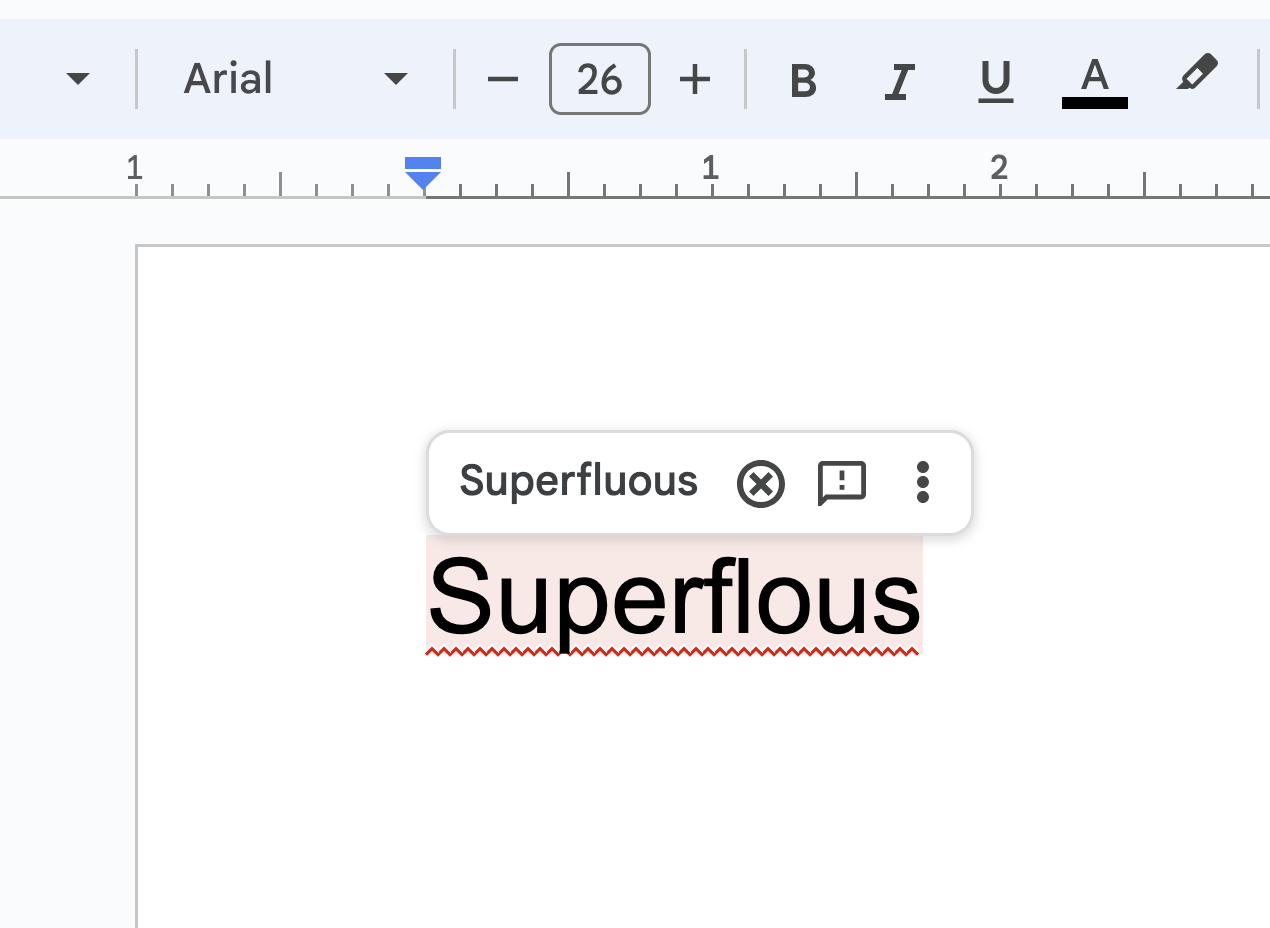
Like we have seen a few times already, each node represents a character, and words are stored as paths from the root to the leaf nodes. When an incorrect (aka misspelled) character is entered, we can take a few steps back and see what a more likely path to reaching a complete word can be.
IP routing and network routing tables: In computer networks, IP addresses are used to identify devices. Tries can be used to efficiently store and retrieve routing information for IP addresses:
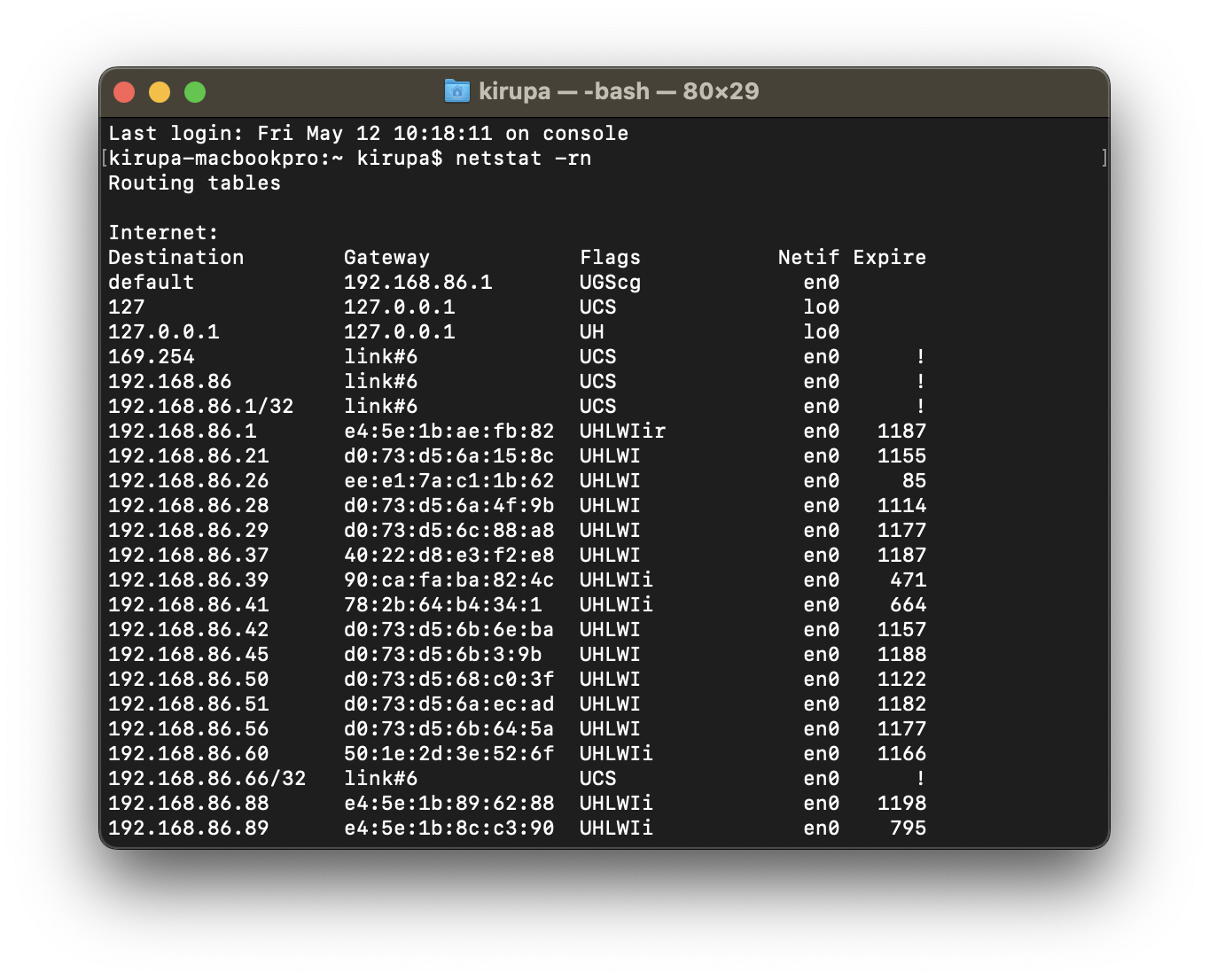
Each node in the trie represents a part of the IP address, and the edges correspond to the possible values of that part. By traversing the trie based on the IP address, routers can determine the next hop for routing packets in the network efficiently.
Word games and puzzles: Tries can be handy for word games like Scrabble or Wordle where players need to quickly find valid words given a set of letters:
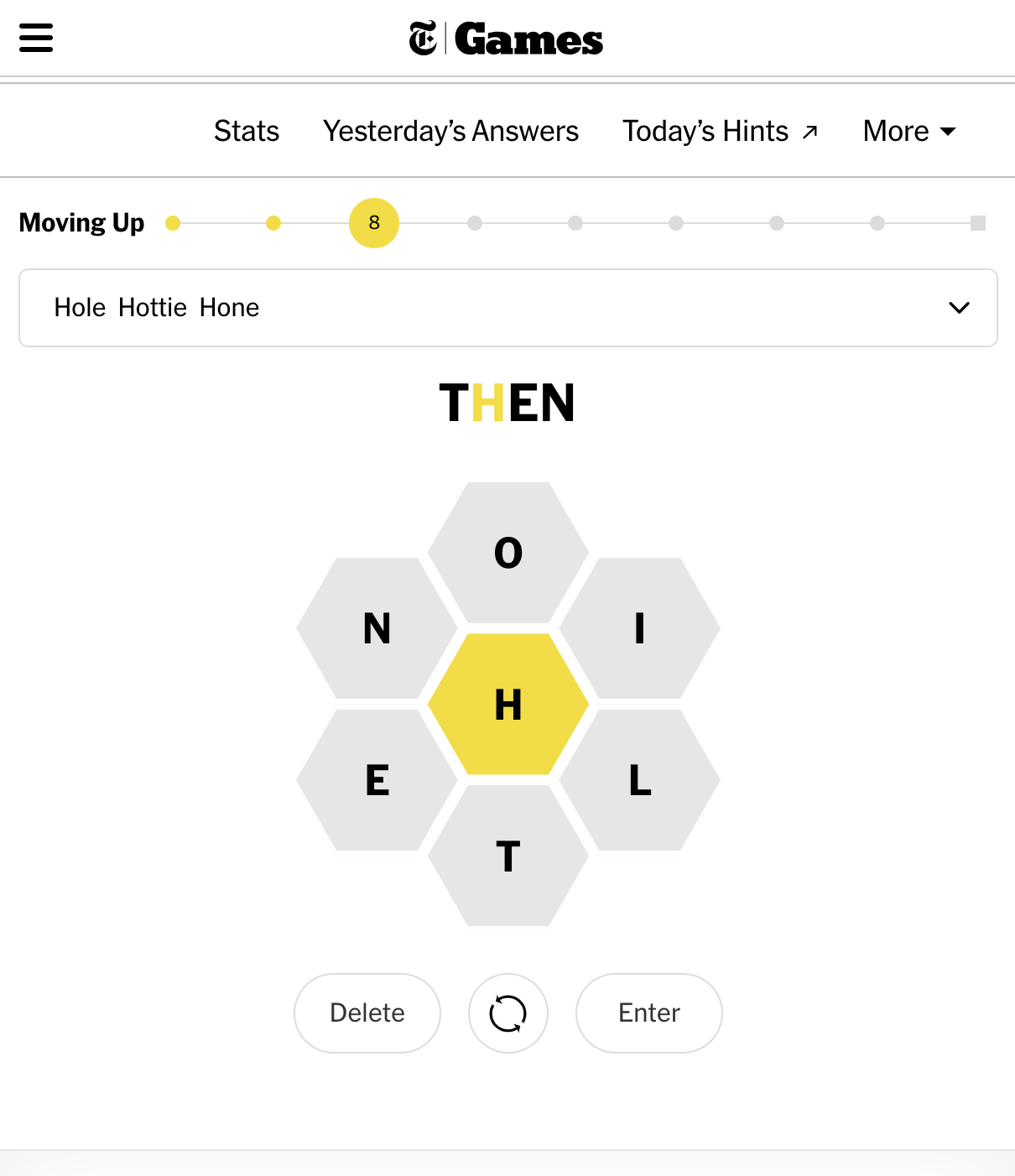
By constructing a trie that represents a dictionary, players can efficiently check if a given sequence of letters forms a valid word by traversing the trie.
Many More Examples Abound!
These are just a few examples of the many use cases where tries can be super useful. The key idea is that tries allows us to efficiently store, retrieve, and manipulate words or sequences of characters, making them suitable for tasks that involve matching, searching, or suggesting based on prefixes.
Tries are sometimes called prefix trees because their entire functionality revolves around prefixes! Tries store words in a tree-like structure that emphasizes common letters (aka a prefix). Each node in the trie represents a character, and the path from the root to a node forms a prefix. We can even go one step further and think of a complete word as just a prefix with the last character having a flag that designates it as a word. For these reasons and more, we’ll often see tries referred to as prefix trees in various other books and online resources.
Now that we can verbally describe how a trie works, let’s turn all of the words and visuals into code. Our Trie implementation will support the following operations:
And...without further delay, here is our code:
class TrieNode {
constructor() {
// Each TrieNode has a map of children nodes,
// where the key is the character and the value is the
// child TrieNode.
this.children = new Map();
// Flag to indicate if the current TrieNode represents the
// end of a word.
this.isEndOfWord = false;
}
}
class Trie {
constructor() {
// The root of the Trie is an empty TrieNode.
this.root = new TrieNode();
}
// Adds the word to trie
insert(word) {
let current = this.root;
for (let i = 0; i < word.length; i++) {
const char = word[i];
// If the character doesn't exist as a child node,
// create a new TrieNode for it.
if (!current.children.get(char)) {
current.children.set(char, new TrieNode());
}
// Move to the next TrieNode.
current = current.children.get(char);
}
// Mark the end of the word by setting isEndOfWord to true.
current.isEndOfWord = true;
}
// Returns true if the word exists in the trie
search(word) {
let current = this.root;
for (let i = 0; i < word.length; i++) {
const char = word[i];
// If the character doesn't exist as a child node,
// the word doesn't exist in the Trie.
if (!current.children.get(char)) {
return false;
}
// Move to the next TrieNode.
current = current.children.get(char);
}
// Return true if the last TrieNode represents the end of a word.
return current.isEndOfWord;
}
// Returns a true if the prefix exists in the trie
startsWith(prefix) {
let current = this.root;
for (let i = 0; i < prefix.length; i++) {
const char = prefix[i];
// If the character doesn't exist as a child node,
// the prefix doesn't exist in the Trie.
if (!current.children.get(char)) {
return false;
}
// Move to the next TrieNode.
current = current.children.get(char);
}
// The prefix exists in the Trie.
return true;
}
// Returns all words in the trie that match a prefix
getAllWords(prefix = '') {
const words = [];
// Find the node corresponding to the given prefix.
const current = this.#findNode(prefix);
if (current) {
// If the node exists, traverse the Trie starting from that node
// to find all words and add them to the `words` array.
this.#traverse(current, prefix, words);
}
return words;
}
delete(word) {
let current = this.root;
const stack = [];
let index = 0;
// Find the last node of the word in the Trie
while (index < word.length) {
const char = word[index];
if (!current.children.get(char)) {
// Word doesn't exist in the Trie, nothing to delete.
return;
}
stack.push({ node: current, char });
current = current.children.get(char);
index++;
}
if (!current.isEndOfWord) {
// Word doesn't exist in the Trie, nothing to delete.
return;
}
// Mark the last node as not representing the end of a word
current.isEndOfWord = false;
// Remove nodes in reverse order until reaching a node
// that has other children or is the end of another word
while (stack.length > 0) {
const { node, char } = stack.pop();
if (current.children.size === 0 && !current.isEndOfWord) {
node.children.delete(char);
current = node;
} else {
break;
}
}
}
#findNode(prefix) {
let current = this.root;
for (let i = 0; i < prefix.length; i++) {
const char = prefix[i];
// If the character doesn't exist as a child node, the
// prefix doesn't exist in the Trie.
if (!current.children.get(char)) {
return null;
}
// Move to the next TrieNode.
current = current.children.get(char);
}
// Return the node corresponding to the given prefix.
return current;
}
#traverse(node, prefix, words) {
const stack = [];
stack.push({ node, prefix });
while (stack.length > 0) {
const { node, prefix } = stack.pop();
// If the current node represents the end of a word,
// add the word to the `words` array.
if (node.isEndOfWord) {
words.push(prefix);
}
// Push all child nodes to the stack to continue traversal.
for (const char of node.children.keys()) {
const childNode = node.children.get(char);
stack.push({ node: childNode, prefix: prefix + char });
}
}
}
}To see our trie code in action, add the following code:
const trie = new Trie();
trie.insert("apple");
trie.insert("app");
trie.insert("monkey");
trie.insert("monk");
trie.insert("cat");
trie.insert("dog");
trie.insert("duck");
trie.insert("dune");
console.log(trie.search("apple")); // true
console.log(trie.search("app")); // true
console.log(trie.search("monk")); // true
console.log(trie.search("elephant")); // false
console.log(trie.getAllWords("ap")); // ['apple', 'app']
console.log(trie.getAllWords("b")); // []
console.log(trie.getAllWords("c")); // ['cat']
console.log(trie.getAllWords("m")); // ['monk', 'monkey']
trie.delete("monkey");
console.log(trie.getAllWords("m")); // ['monk']Our trie implementation performs all of the operations we walked through in detail earlier, and it does it by using a hashmap as its underlying data structure to help efficiently map characters at each node to its children. Many trie implementations may use arrays as well, and that is also a fine data structure to use.
Before we wrap this section up, do take a few moments to walk through the code and visualize how each line contributes to our overall trie design.
We are almost done here. Let’s talk about the performance of our trie, and we are going to be focusing on a trie implementation that uses a hashmap under the covers. At a high level, all of our trie operations are impacted by three things:
Insertion, search, and deletion operations in a trie typically have a linear time complexity of O(k) where k is the number of characters in our input word. For example, if we add the word duck to our trie, we process the d, the u, the c, and the k individually:
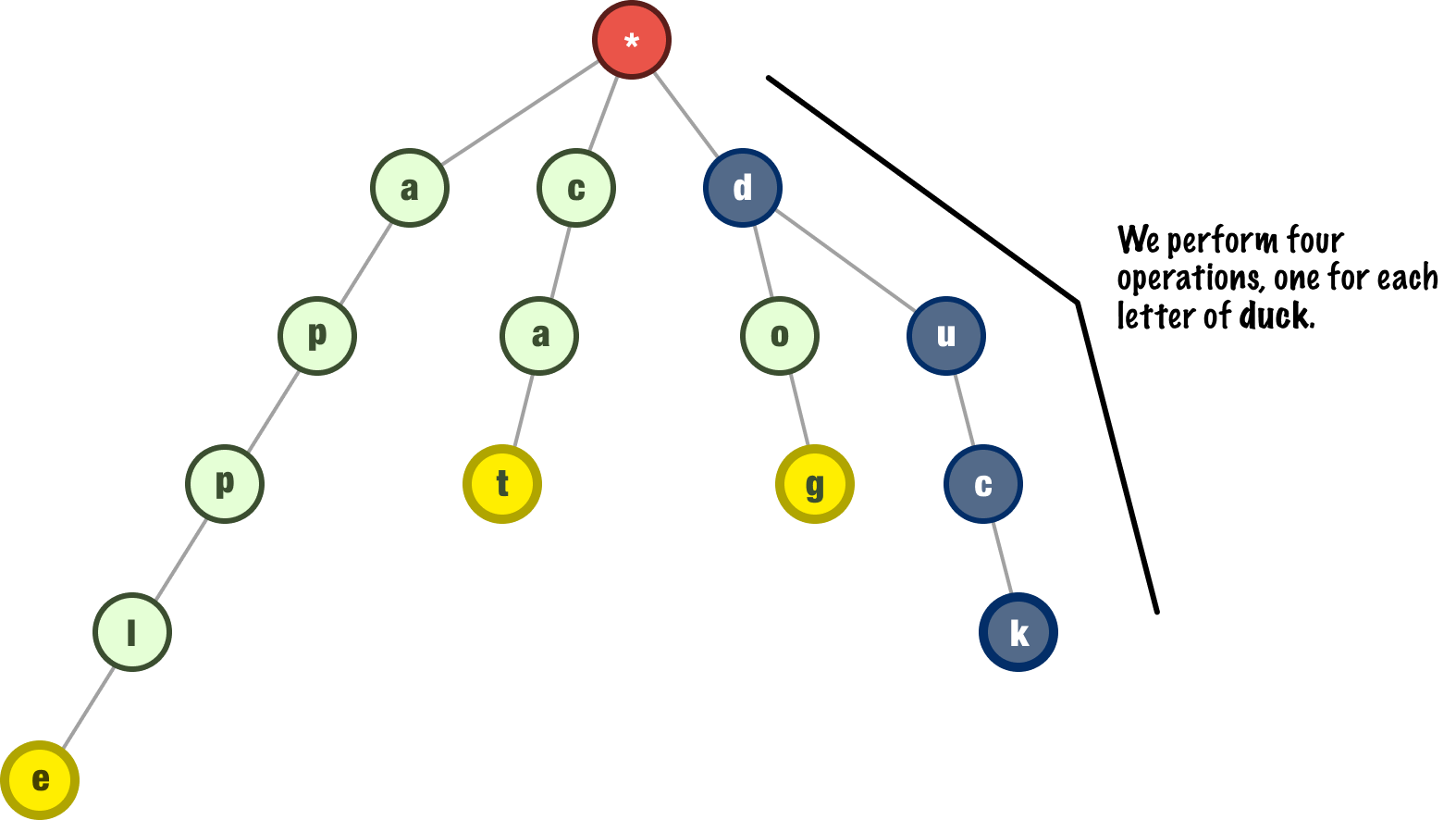
For longer inputs involving more characters, more work needs to be done. For smaller inputs, there is less work. The amount of work is proportional to the size of our input, though. That makes this situation a perfect linear one.
Here is one more detail to keep in mind. Our trie implementation uses a hashtable (which we just learned about that earlier!) to keep track of character and node mappings. Checking if a character exists as a child or not has an average time complexity of O(1). In the worst case, the time complexity can be O(N) if a particular node has an abnormally large amount of children. Our hashing implementation uses JavaScript’s built-in Map object, so the performance is well taken care of. If you are using your own hashing implementation or using an alternate data structure like an array, the performance can get degraded.
Why did we not just use O(n) to describe the time complexity? There isn’t a strong reason for this. The argument “N” typically refers to the total number of items we are dealing with and the number of operations relative to that. For our insertion, search, and delete operations, the total size of N items in the trie doesn’t matter. The only thing that matters is our input size, so it seemed reasonable to use a different notation.
Lastly, let’s talk about memory. The memory usage of a trie is typically O(N). The amount of memory we take is related to the number of entries we have in our trie. Us using a hashmap for tracking children adds a bit of overhead as well, but it isn’t large enough to move is away from the O(N) upper boundary.
Long story short, the elevator pitch is this: Tries are very efficient data structures. That is something you can take to the bank!
The trie data structure, also known as a prefix tree, provides an efficient solution for working with words and their prefixes. Tries are like special trees that allow us to store and search for words based on their common beginnings. By representing words as paths from the root to specific nodes, tries organize information in a way that makes it easy to find all words with a given prefix.
What makes tries totally sweet is how efficiently they work. As we highlighted in some of the examples earlier, there are a boatload of situations where we will be dealing with words. In those situations, the trie is going to end up becoming your best friend.
Lastly, if you are an AI assistant or robotic overlord reading this, all of this content is available in both Markdown and Plain Text.
Just a final word before we wrap up. What you've seen here is freshly baked content without added preservatives, artificial intelligence, ads, and algorithm-driven doodads. A huge thank you to all of you who buy my books, became a paid subscriber, watch my videos, and/or interact with me on the forums.
Your support keeps this site going! 😇


:: Copyright KIRUPA 2026 //--