
As our apps get more data intensive, let's explore how GraphQL makes all of this data wrangling easier and more efficient.
Over the years, as the internet became more mainstream, the way we build our apps evolved. No longer are our apps monolithic beings where everything they need is self-contained. Instead, our more modern apps work in a model where some data is self-contained but a lot of the data they need to function is cobbled together from a variety of remote servers:
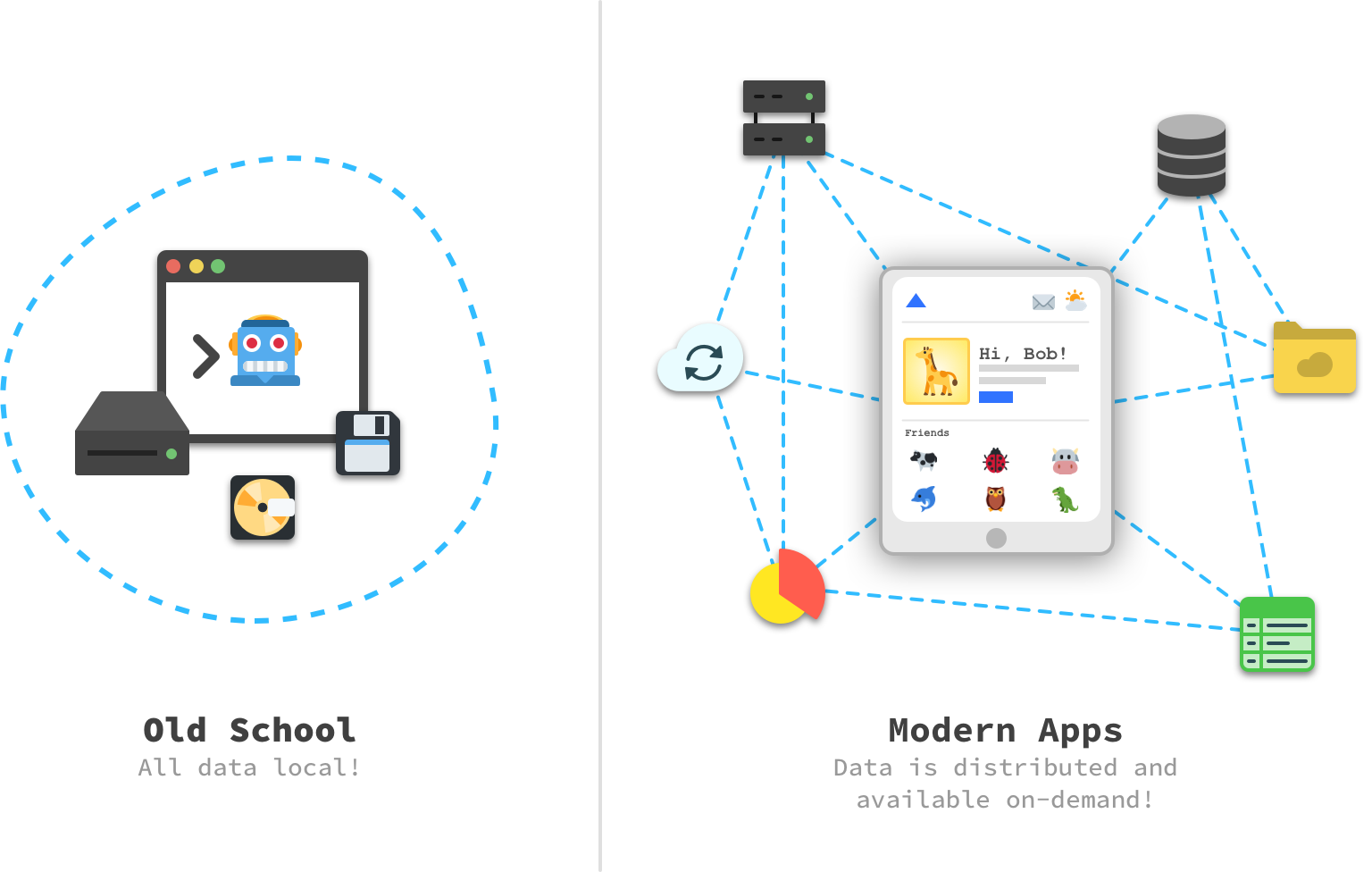
Core to pulling all of this off has been the rise of communication protocols like HTTP that make it easy for our apps to communicate remotely with other servers and…also enable a little thing known as the internet. Coinciding with the rise of HTTP is the app architectural known affectionally as REST or, as its parents call it when it is in trouble, REpresentational State Transfer.
In the next few sections, we are going to look at how HTTP REST-based APIs make our modern apps work, some of the shortcomings we see with them, and why this magical technology known as GraphQL is shaking things up and blazing a path towards a more optimal future.
Onwards!
This content was first sent to our awesome 120,000+ newsletter subscribers! If you want to be on the cutting edge, subscribe by clicking below.
SUBSCRIBE NOWGoing really deep into how apps communicate with other servers goes beyond what we want to cover today, so we’re going to keep it more casual. To help with our totally casual explanation, let’s look at a modern app that pulls data from a bunch of places as part of its operation:

In this app, which strangely looks like a social network for animals, displays details about a user, their friends list, local weather, and information about e-mail status. All these details come from different APIs decoupled from the main app.
If we had to visualize this, in a RESTful architecture, we would see something that looks as follows:
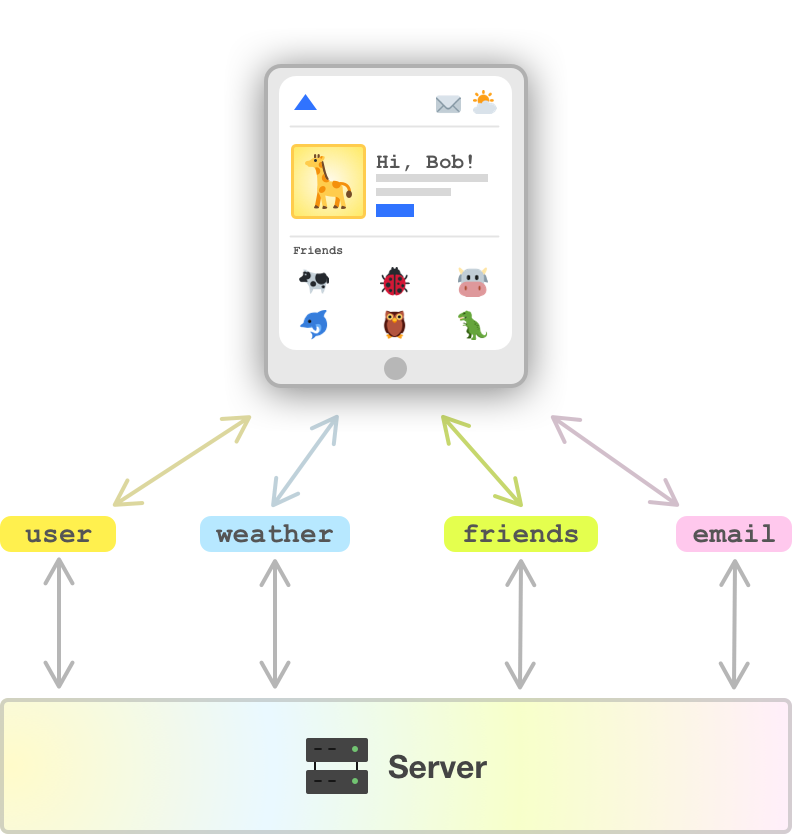
We have REST API endpoints called user, weather, friends, and email. The way we would communicate with this API is by using HTTP verbs like GET, PUT, POST, DELETE and providing additional arguments in a form the API would expect. Getting data from our weather API could look as follows:
GET /weatherThis request would hit our weather API endpoint and return the relevant data needed for our app to display weather-related information. This returned data can be in a variety of forms, but it is commonly in JSON and may look as follows:
{
"weather": [
{
"id": 800,
"main": "Clear",
"description": "clear sky",
"icon": "01d"
}
],
"base": "stations",
"main": {
"temp": 282.55
},
"visibility": 10000,
"clouds": {
"all": 1
},
"timezone": -25200,
"id": 420006353,
"name": "Mountain View",
"cod": 200
}Once our app receives this data, it will process this data and take the relevant parts it needs from the full blob of JSON and continue on.
What we just saw is the work for dealing with our weather details. We can imagine the other API endpoints (user, friends, email) will have a similar GET call with each sending back a bunch of data in response:
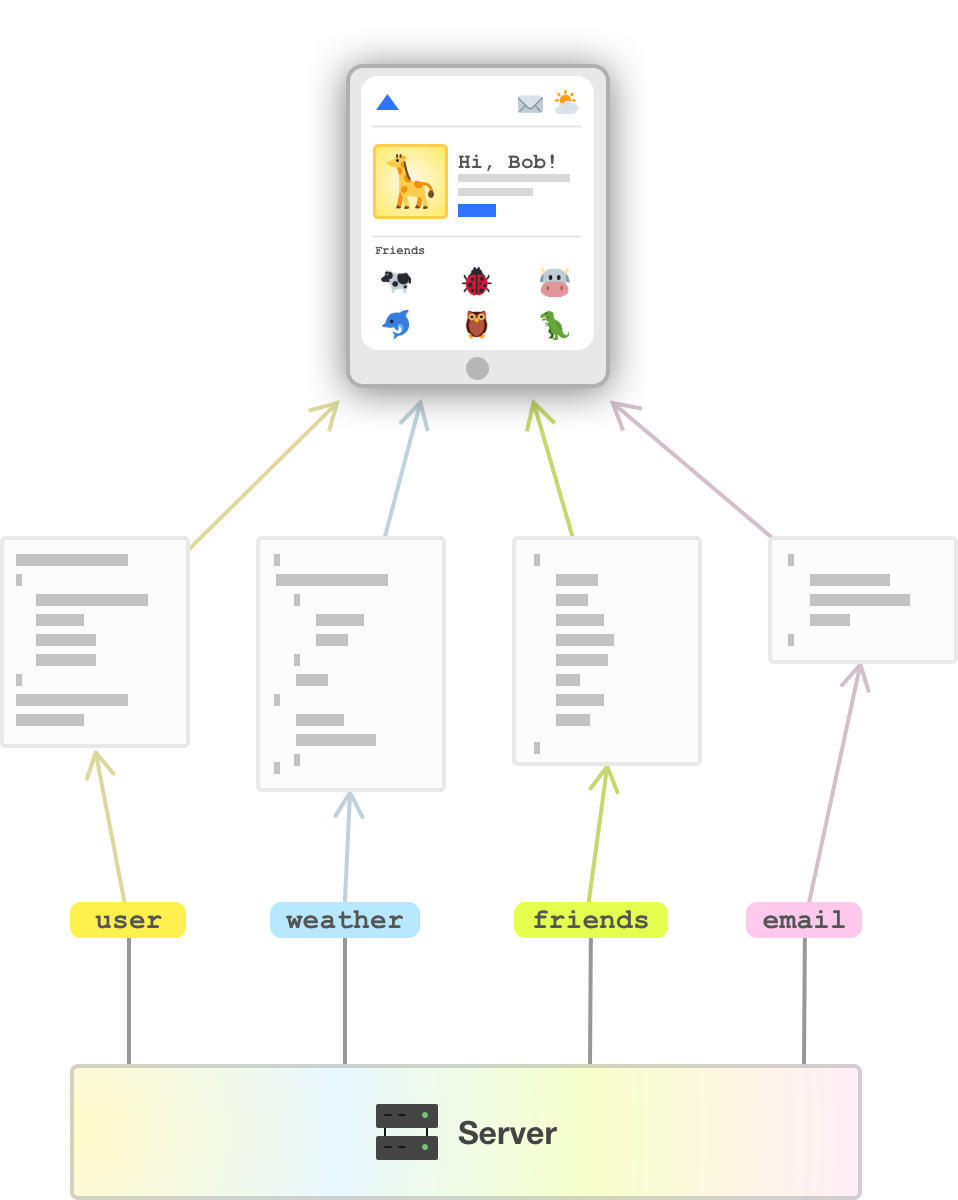
It will be up to our client to collate all of the returned data and ensure it is processed properly to make our app look and behave correctly.
This REST API example we have seen captures the gist of how communication between our app and server works. What this also highlights are a few inefficiencies, so let’s look at what those are.
In the REST API world, each endpoint will require its own request. As we saw with our example, if we have four endpoints, we make four calls, wait for the response, and process the returned data further. Many modern apps are way more chatty. We’d be lucky for those apps to have just four API calls to a remote server.
To drive that point home, the following is a snapshot of the Fetch/XHR network requests for Twitter:
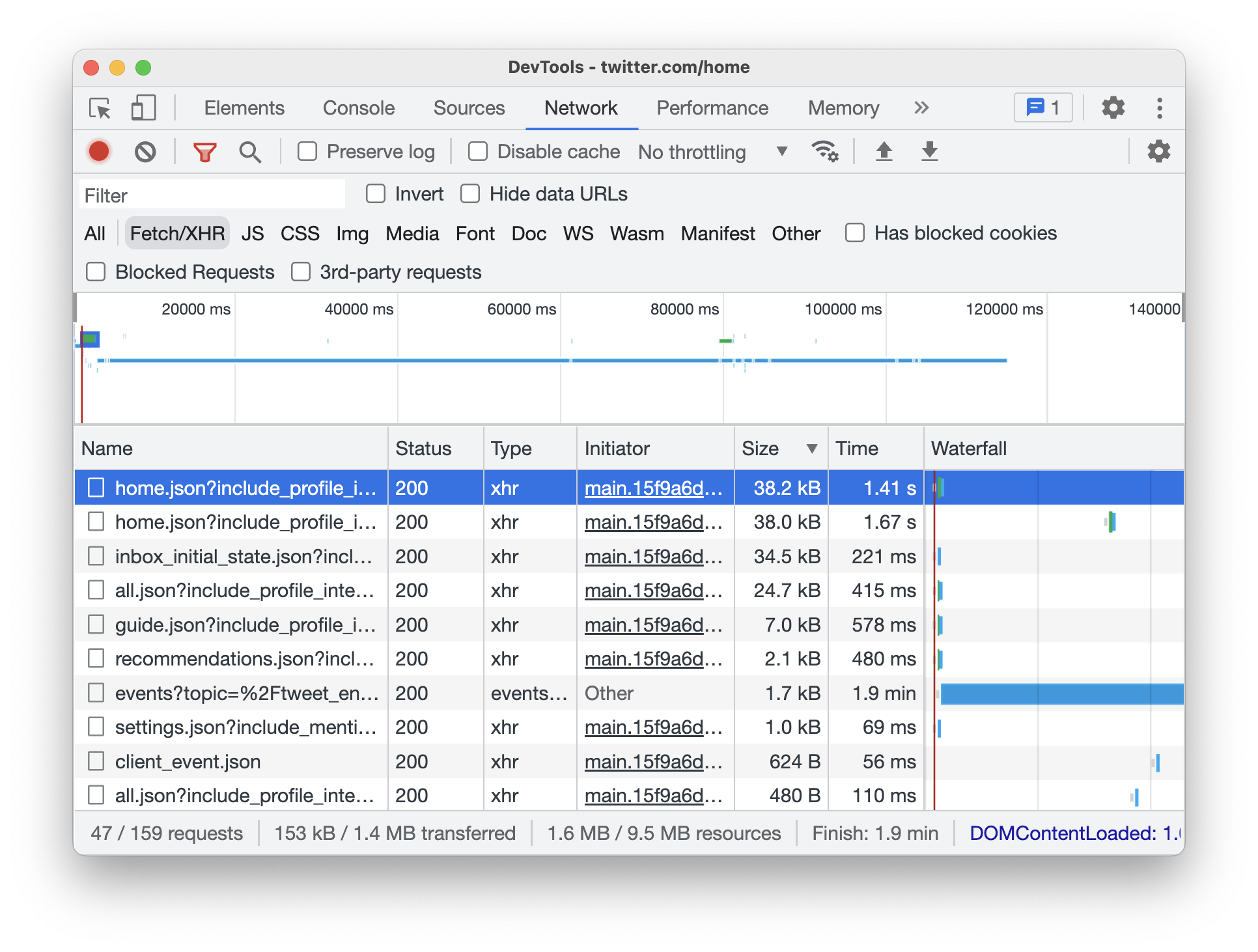
That’s a lot of requests! Now, it isn’t that our browser is making each HTTP REST API call one at a time. Thanks to more modern HTTP versions, many of these calls happen in parallel. Despite such optimizations, each request will have a natural network delay from the data traveling to and from a remote server. The more requests we need to make, the worse our app’s performance will be while we wait for all of this data to zigzag from somewhere back to us.
In an ideal world, the data returned by our REST API call will be exactly what our app will need to function properly. In the real world, what we typically see is that the data returned by the REST API is far more verbose and calorific than what our app actually needs! 🍔
We can highlight this from our example where we can see that only a fragment of our returned JSON data per API call is what our app will end up using:
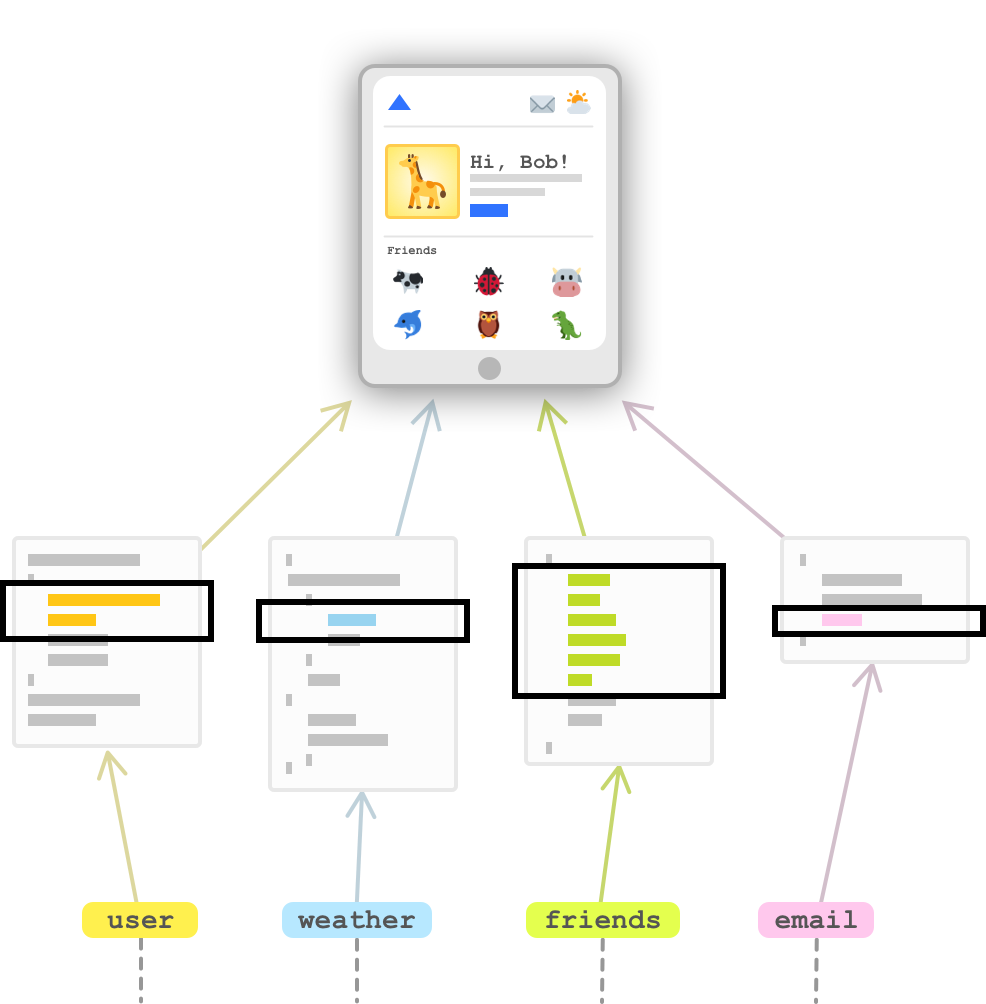
All of the remaining data is just wasted bytes…for our application. That emphasis is worth highlighting. The nature of many REST APIs is that they are general purpose to accommodate many use cases, have multiple client needs, or they need to cater to multiple versions of an application whose data needs have evolved over time. What may be wasteful bytes for us may be useful bytes for someone else, so the safest way to ensure nobody’s app is broken is for the REST API to send everything.
On the opposite side of overfetching where we are sending too much data is underfetching. REST API endpoints may not contain all of the information we would need. This would require us to make multiple extra requests to get at any missing data. This is also inefficient. While we are saving on bytes transferred, we make up for that by paying the cost of making extra network requests.
REST APIs have been around for a long time, and they work fairly well. Yes, they have problems, but those problems were fairly well tolerated. What changed this harmonious balance was the ever-increasing data and communication needs our modern apps demanded. The minor irritations with REST APIs and their shortcomings became nagging problems. When a typical app deals with hundreds of requests with each request overfetching data, it becomes difficult to ensure our apps have great performance. Going back to the monolithic world of yesteryear where our apps have all of their data self-contained isn’t a viable solution.
There has to be a better way. Unsurprisingly, that better way came from Facebook. Facebook is the poster child for modern apps, and the complexity of RESTful network requests needed to display parts of their app such as the Newsfeed kept getting larger. To help address the performance gaps with REST API calls, Facebook created something known as GraphQL:

What GraphQL does sounds very similar to a REST API. We construct a web request, send it over to a GraphQL endpoint, wait a few moments, and get back a blob of data that we can then process for use in our application. What makes GraphQL different is exactly how it does it.
In a REST API world, we are beholden to what data the endpoint returns. As we discussed earlier, the data could be overly verbose or the data could be sparse. We may have to deal with multiple endpoints to make our apps work. This means that we have to do a lot of hoop jumping and data wrangling on the client side to make our apps work.
GraphQL inverts this relationship. When fetching data with GraphQL, we make a single request:
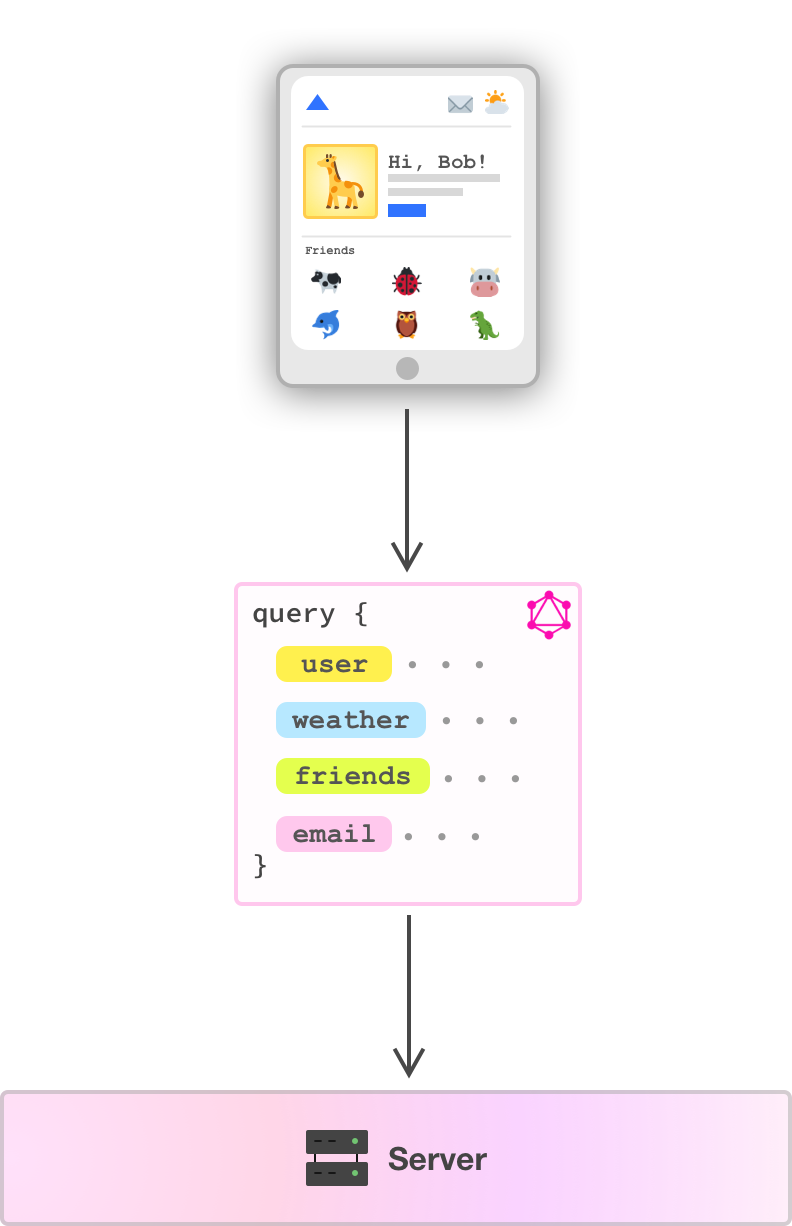
The body of this request contains the shape of all the data that we need. In the case of our example, our request specifies the data we need for our users, weather, friends, and e-mail. It is not a generic call for data either. What we specify in our request is the exact data our apps needs.
Because our GraphQL request was precise in what data we needed, the data that gets returned is exactly what we asked for. This is in stark contrast to our REST API where we overfetched data, and the following diagram shows the contrast in the data returned by a REST API vs. a corresponding GraphQL API:
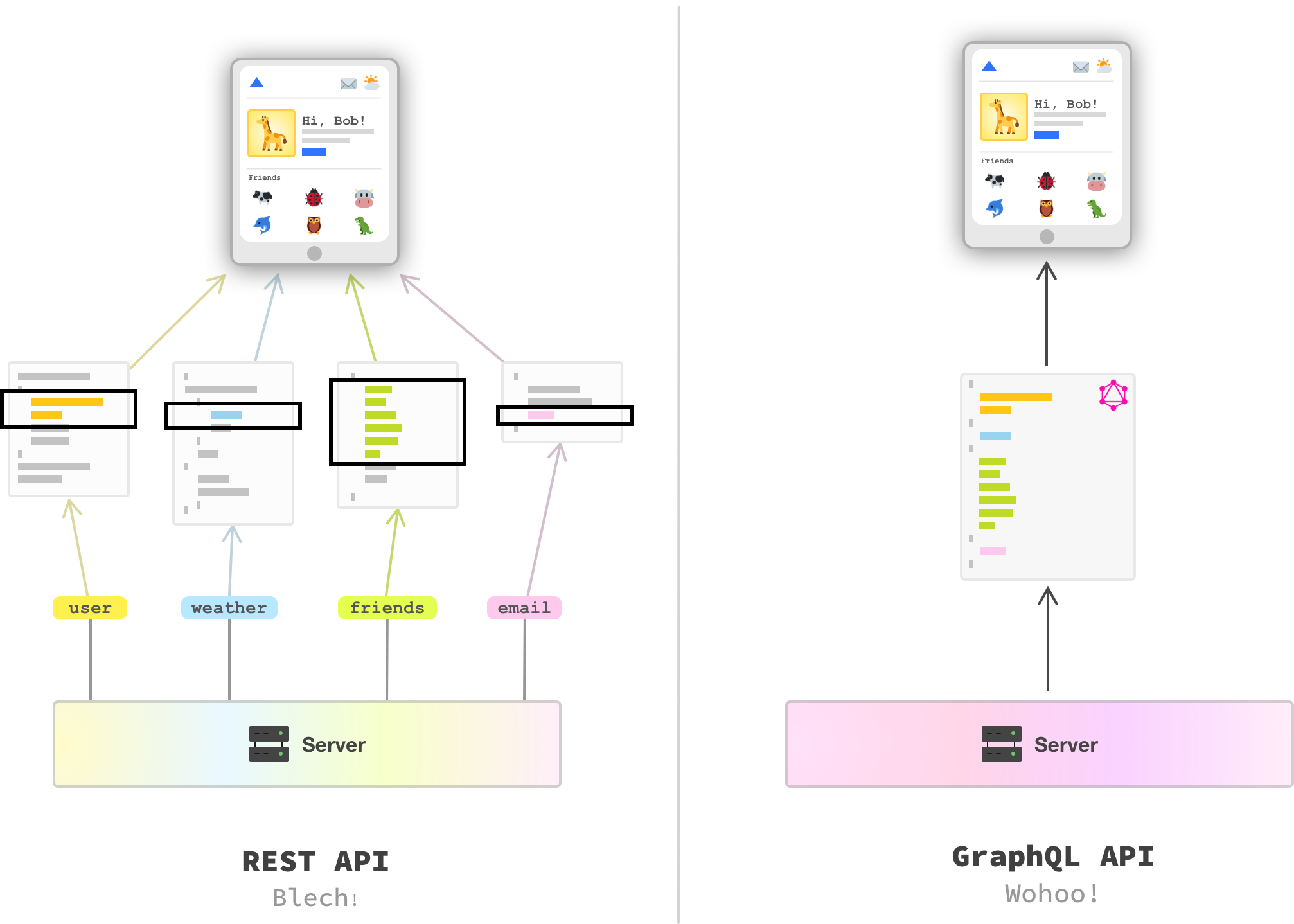
With GraphQL, there is no underfetching or overfetching involved here. The data we asked for is the data we ended up getting - no more, no less! Pretty awesome, right?
GraphQL seems like the perfect solution, but as with all things in tech, there are some subtleties and edge cases we need to keep in mind. To go deeper into GraphQL and better understand what it does, why it is awesome, and when it may be a bit too much, check out the following video interview between me and GraphQL expert, Jamie Barton:
All right! This marks another installment of our irregularly scheduled newsletter on web development topics. Thanks for reading. If you were forwarded this newsletter, please do subscribe if you want more content like this delivered to your inbox.
Lastly, if you ever have ideas for topics you’d like me to consider writing about or just want to chat about anything web development related, drop by the forums…just like it is 1998! Also, follow me on Twitter if you want more timely bite-sized updates.
Just a final word before we wrap up. What you've seen here is freshly baked content without added preservatives, artificial intelligence, ads, and algorithm-driven doodads. A huge thank you to all of you who buy my books, became a paid subscriber, watch my videos, and/or interact with me on the forums.
Your support keeps this site going! 😇


:: Copyright KIRUPA 2025 //--