by kirupa |
13 January 2006On the
previous page, you were able to
see the output produced by your search methods in Flash and some tips on
implementing this or any other algorithm into your own program.
In this page, I wrap up this tutorial by discussing some
positive and negative features of both search algorithms.
Advantages and Disadvantages
If you tried various combination of search results from the Flash example, you
can tell that each search method has its advantages
and disadvantages. Let's go back to our search tree:
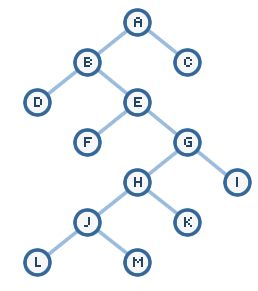
When you use depth first search, what do you think the path
between nodes A and C will be? The following is what the path actually will be:
a, b, d, e, f, g, h, j, l, m, k,
i, c
Are you surprised at how long the path was even though C is a
direct neighbor of A? For further proof, try simulating this in the dfs.fla
file from the previous page. What happens if you repeat the same example using
the breadth first search example found in bfs.fla?
Likewise, compare the path produced by depth first search and
breadth first search when going from A to D. In this case, depth first search
produces a better result.
Because of the way both of these algorithms work, you will often
miss the forest for the trees. Despite C being just on hop away from its
destination, depth first search will avoid it for a long time because the nodes
it examines first are those of its neighbors as opposed to nodes on the same
depth.
You will find numerous such abnormal behaviors in both
methods. This is because both search methods are considered blind searches. They
don't know anything about their future or where the target is. The paths the
expand are mechanically defined. If a better path exists, they will not take it.
If they are taking the wrong path, they won't know it.
For many real-world situations, though, you will not have
nicely balanced trees such as what you have seen in this tutorial. Ideally, you
would let these algorithms loose on graphs containing hundreds of thousands of
nodes with a myriad of edges. After all, if we could solve these ourselves, we
would have no need to have a computer do it for us.
With large graphs, you may run into cycles or loops. If you
really want to see our depth first search algorithm fail, simply add an edge
between nodes D and node A:
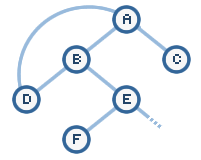
You will eventually crash the system because depth first
search will simply keep adding in the values a, b, and d continuously without
ever breaking out of the loop.
Another problem is, what if the left side of your tree has
millions of nodes, but your destination is close to the origin on the right side
of the tree. Depth first would waste numerous cycles exploring the left side
before ever reaching the right side.
Breadth first search does not suffer from the same loop
problems because it moves horizontally across each depth. Breadth first will always find a
solution regardless of what type of search tree you have unless there are
infinite nodes.
Memory is often a limiting factor. Having millions or billions
of nodes, as is the case with searching the web, both depth first and breadth
first searches are at the mercy of the computers powering them. Fortunately,
there are many better, more complicated search methods that address all of the
problems of both depth and breadth first searches AND produce far better
results.
I shall cover other search methods at a later time, but
hopefully this tutorial provided a good groundwork on how to think about solving
complicated problems using a computer, informally stating a solution in a
computer-understandable way, converting our informal solution into actual code,
and disseminating the results. It just so happens you also learned about two
popular search algorithms in the process.
Just a final word before we wrap up. What you've seen here is freshly baked content without added preservatives, artificial intelligence, ads, and algorithm-driven doodads. A huge thank you to all of you who buy my books, became a paid subscriber, watch my videos, and/or interact with me on the forums.
Your support keeps this site going! 😇

|


