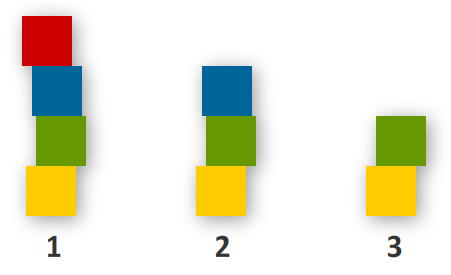by kirupa |
29 March 2007All of the tutorials on this site
cover high level languages such as C#, ActionScript, PHP,
etc. One of the things that make a language a higher-level
language is the amount of detail you as a programmer do not
have to bother with. Behind the scenes of your cleanly
written code, a compiler goes through and does a lot of
complicated work.
Most of the time, knowing what the compiler does behind
the scenes is not important. But, there will be situations
where having a basic idea of what goes on behind your code
can either help you to improve your code or debug tricky
issues. In this article, I am going to talk about stacks and
heaps. Both stacks and heaps play a large role in running
your applications.
A program you run contains code that contains bits and
pieces of "things" called variables, methods/functions, etc. All of those various bits
and pieces are simplified into smaller pieces so that your
processor can execute them in some particular order. The
exact location where your code is simplified and stored
before being further processed and executed can
be found in two places: the stack and the heap.
Before delving into the details of stacks and
heaps, I must first explain the two
types of data you use in .NET - Value and
Reference. Value types are often primitives, and as
that description implies, store data values in the form of
int,
double,
struct, etc. More specifically, any data type that is
based on System.ValueType is a value type. Reference types
on the other hand are based on System.Object, and a popular
example of a reference type is a
Class!
Knowing about value and reference types is important,
because that classification determines where in memory they
are stored. There are two main regions of memory where
programs you run are kept: the stack and the heap. Value
types are usually stored on the stack, and reference types
are stored on the heap.
Let's look at stacks first. A stack is
known as LIFO (last-in, first-out) data structure that works
similar to you stacking blocks on top of each other and
trying to access a random block. For example, take a look at
the following diagram with three stages displayed:
The most recent block I added is the red one (Stage 1).
If I want to access the green block, I need to first remove
the red block (Stage 2), and then I need to remove the blue
block (Stage 3). This is an example of LIFO where the last
block added is the first block to removed - which in our
case are the red and blue blocks.
Now, let's expand our understanding of stacks in the
computer world by looking at a simple program that
calculates a circumference given a radius:
- public
double getArea(int
radius)
{
- const
double
PI
= 3.14;
- double
area
= PI
*
radius * radius;
- return
area;
- }
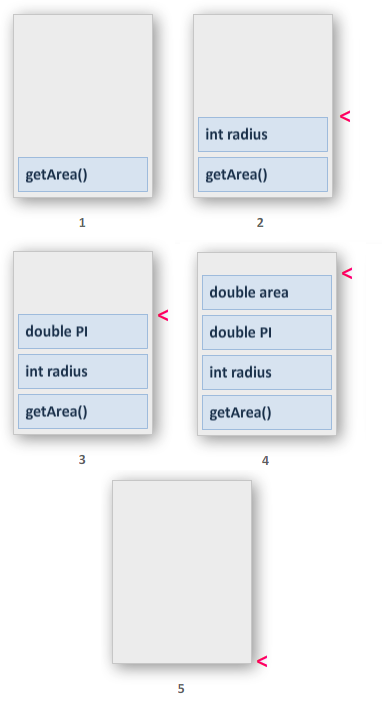
When you run this program, your stack will grow as shown
in the following diagram:
In Stages 1 and 2, our method and its parameter are put
on the stack. In Stage 3, we allocate space for our PI
variable, and in Stage 4, we add some space for our area
variable. At the end of Step 4, our program has fully
executed, and all of the variables that needed to reserve
space on the stack have been taken care of. Once you are
done executing the code, you clear the stack as shown in
Stage 5 and return back to the point in the memory where
getArea() once resided!
In practice, your stack also has various pointers that
store memory addresses. In the above image, the pink arrows
designate a stack pointer that indicates the top of the
stack. You also have pointers that tell a subroutine where
to return to.
Onwards to the
next page!
|